INTRO
트렌드를 따라가기 위해 많은 사람들이 뉴스를 봅니다.
하지만 하루만해도 수백 수천개의 뉴스가 올라오고 그 중 어떤 뉴스가 중요한 뉴스인지 파악하기는 쉽지 않습니다.
한국 뉴스를 통해 트렌드를 파악하는 것도 힘든데 해석하기도 어려운 해외 뉴스를 보고 트렌드를 파악하는 것은 더 어려울 것 입니다. 그렇기 때문에 수 많은 뉴스를 주제별로 묶어서 핫한 주간, 월간 뉴스를 쉽게 파악해보고자 합니다.
BERTopic
- Topic Modeling 기법 중 하나입니다.
- BERT 기반 Embedding + Class-based TF-IDF를 사용한 것이 아이디어의 핵심입니다.
구조

BERTopic의 구조는 크게 세 단계로 볼 수 있습니다.
1. BERT를 이용해서 각 Document에 대해서 Embedding을 합니다.
2. UMAP을 이용해서 각 Document Vector의 차원을 축소합니다.
3. HDBSCAN을 이용해서 클러스터링을 합니다.
이 때 Clustering을 통해서 각 Document Vector에 대해서 유사한 Document끼리 묶어주는 과정을 진행합니다.
그 다음에 C-TF-IDF를 통해서 각 묶어진 그룹(Topic 또는 Class)에 대해 해당 Topic을 잘 표현하는 단어를 찾습니다.
마지막으로 Maximize Candidate Relevance Algorithm을 이용해서 적절히 Topic을 대표하는 Keyword들이 최대한 다양하게 선별되도록 조정합니다. Document, Word Embedding Vector에 대해서 Similarity를 계산해서 Keyword List를 Return 합니다.
데이터 수집
데이터 수집 사이트 : CNBC
사용 툴 : Python(bs4, requests, lxml, selenium 등)
- 다양한 라이브러리를 사용한 이유는 각 사이트마다 설계 구조가 다르기 때문에 원하는 정보를 가져오기 위해 다양한 방법을 사용했습니다. 클릭과 스크롤을 내리는 작업이 필요한 경우에는 selenium을 선택했고 그 외에는 접근이 쉽고 속도가 빠른 requests, bs4, lxml 등을 활용하였습니다.
*동적 크롤링이라 불리는 selenium의 경우 다양한 작업을 수행할 수 있지만 속도가 굉장히 느립니다.
수집 아이템 : news date(날짜), news contents(기사), news headline(제목)
데이터 전처리
1. CNBC 원본 데이터

02-13 글을 작성하는 현재를 시점으로 직접 수집한 CNBC 뉴스 기사입니다.
여기서 몇 가지 전처리를 진행해 보도록 하겠습니다.
2. CNBC 데이터 전처리

우선 DATE를 보면 시간 분 초 정보는 필요가 없으므로 제거 해주고 데이터 타입을 datetime으로 변환해줬습니다.
그리고 drop_duplicates함수를 사용해 DATE(날짜), TEXT(뉴스 기사)를 기준으로 중복된 행을 제거 해줬습니다.
다음으로 수집한 데이터에는 없었지만 nan값이 들어간 경우도 있기 때문에 결측치를 제거 해주도록 합니다.
이제 뉴스 기사와 제목의 텍스트 전처리를 진행해보도록 하겠습니다.
뉴스 기사와 제목에는 특수문자와 공백이 2칸 이상 등 전처리가 필요한 부분들이 있습니다. 이를 제거하는 것이 좋으므로
re 라이브러리와 정규 표현식을 사용해 제거해주도록 하겠습니다.
[^A-Za-z0-9가-힣] -> 한글, 영어, 숫자만을 포함한다는 의미입니다.
' + ' -> 공백이 2개 이상인 모든 것들을 의미합니다.
이제 저 두 조건을 만족하지 않는 것들을 re.sub 함수를 통해 각 행의 뉴스마다 apply 함수를 이용해 제거해줍니다.

그러면 이렇게 DATE의 시간 분 초 정보는 사라지고 TITLE, TEXT에 쓸데없는 이모티콘과 공백들이 제거 됐습니다.

이제 마지막으로 앞서 datetime으로 DATE의 데이터 타입을 변환해줬으니 원하는 기간의 뉴스만 필터링 해줍니다.
여기서 저는 1월1일부터 2월12일까지 1달 정도로 필터링 했습니다.
그럼 이제 뒤에 나오는 토픽은 월간 토픽이 되겠지요?
형태소 분석 모델 세팅 (Spacy)
다양한 형태소 분석 모델들이 존재하는데 저는 Spacy를 사용했습니다
1. 형태소 분석 모델 다운로드

처음 spacy를 설치했다면 spacy의 형태소 분석 모델을 다운로드 하도록 합니다.
여기서 모델의 크기마다 sm, md, lg가 있고 추가로 transformer pipeline(roberta-base) trf 버전이 있습니다.
저는 여기서 모델의 크기는 크지만 가장 잘 나온다고 생각한 en_core_web_lg를 사용했습니다.
하지만 속도가 비교적 느리고 sm, md 모두 성능은 비슷하므로 여건에 맞게 사용하시면 될 것 같습니다.
2. 형태소 분석 모델 세팅

앞서 spacy 모델의 다운로드를 진행했다면 spacy.load를 통해 다운로드한 모델을 불러오도록 합니다.
그리고 불용어 spacy모델 내의 stop_words 리스트가 defalut 값으로 저장돼있는데 이를 리스트로 저장할수도 있습니다.
저장한 리스트에 내가 원하는 불용어를 새로 추가하여 사용하시면 됩니다.
그리고 nlp.get_pipe('attribute_ruler')처럼 규칙들을 추가해줄 수도 있으므로 자신의 task에 맞게 사용하시면 됩니다.
BERTopic 모델 실행
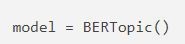
이런식으로 간단하게 모델을 사용할수도 있습니다.
이미 default값으로 파라미터 세팅이 잘 돼있기 때문에 그대로 사용하셔도 괜찮은 성능을 보입니다.
1. customizing BERTopic

맨 처음 BERTopic구조의 embedding model부터 umap model, hdbscan model 모두 직접 파라미터를 세팅할 수 있습니다.
가끔 문서의 수가 너무 적을 경우 직접 파라미터를 조정할 필요가 있어서 저는 상황에 맞게 따로 파라미터를 조정하면서 사용하고 있습니다. umap_model의 metric 역시도 default값은 euclidean이지만 cosine이 저는 더 성능이 좋아서 사용하고 있습니다. 각자 테스트를 해보시고 마음에드는 결과가 나오는 값을 설정해주시면 될 것 같습니다.
embeddinng_model의 경우 다양한 SBERT모델이 있는데 저는 여러개를 테스트해본 결과 tfhub의 모델을 사용했습니다.
https://www.sbert.net/docs/pretrained_models.html
그 외에도 다양한 모델과 방법들이 있으므로 다음 문서를 정독해보시는 것도 추천합니다.
https://maartengr.github.io/BERTopic/getting_started/embeddings/embeddings.html
이제 embedding_model까지 세팅을 해줬으면 BERTopic()안에 위 처럼 넣어주도록 합니다.
top_n_words는 뽑힌 최종 토픽 list의 keywords를 몇개까지 볼 지 설정하는 파라미터 입니다. 파라미터의 갯수가 달라질 수록 신기하게도 결과값이 조금씩 달라지기도 합니다.

해당 문서가 어떤 토픽에 얼마의 확률로 속하는지 계산하기 위해서는 위의 옵션을 True로 설정해주셔야 합니다.
하지만 이 기능이 필요 없다면 False로하고 진행해주시면 속도가 향상 됩니다.
2. BERTopic fit_transform

이제 세팅한 BERTopic에 fit_transform을 이용해 뉴스의 기사나 제목을 넣어줍니다. (여기선 기사를 넣어줬습니다.)
3. BERTopic update_topics

BERTopic의 경우 사전 전처리보다 사후 전처리가 더 효과적일 수 있다는 글을 봤습니다.
fit_transform 이 후, update_topics()를 활용해 전처리를 진행해보도록 하겠습니다.
custom tokenizer을 사용합니다. 키워드로 주제를 파악하기 위해서는 명사나 동사만 있어도 충분하므로 부사, 형용사 등 불 필요하다고 판단되는 품사는 제거하도록 합니다.
그리고 영어의 경우 plays, playing 등 다양한 형태가 존재하므로 lemma_.lower()을 사용해 품사의 원형과 모든 문자를 소문자로 변환해줍니다.
다음으로 앞서 지정해둔 불용어 사전 리스트를 활용해 리스트 안에 있는 단어는 제외하도록 합니다.
다음은 entity 타입이 'TIME', 'CARDINAL', 'DATE', 'PERSON' 등 불필요하다고 판단되는 entity를 제외 해주도록 합니다.
이제 정의한 custom tokenizer을 TfidfVectorizer()안에 넣어주도록 합니다. (CountVectorizer()도 동일하게 가능)
TfidfVectorizer 파라미터는 다른건 넘어가고 ngram_range(1,2)로 돼있는데 (1,1)로 설정해주셔도 무방 합니다.
ngram의 범위를 1개만 볼지 2개를 볼지 설정하는 것인데 상황에 따라 (1,2)가 좋을 때도 (1,1)이 좋을 때도 있습니다.
마지막으로 custom한 TfidfVectorizer() 모델을 update_topics에 넣어주고 2의 과정에서 나온 topics와 TEXT를 넣어 주시면 BERTopic 모델의 토픽을 업데이트 합니다.
BERTopic 결과

Topic이 62개까지 나왔지만 너무 길어질거같아서 10개만 짤랐습니다.
Topic의 top 4의 키워드로 생성된 Name 컬럼입니다. BERTopic을 사용하기 전 LDA, SVD등 여러 토픽 모델을 사용해봤는데 이렇게 깔끔하게 나오는 것은 없었습니다. 대충만 봐도 어떤 주제의 토픽인지 알 수 있겠죠?
-1 이상치라고 보시면 됩니다.
0. 전기차
1. 비트코인
2. 항공
3. 해고
4. 연준, 인플레이션
5. chatgpt
6. 실적
7. 세금
8. 애플
9. 주식 시장
딱 1월과 2월 사이의 핫했던 주제끼리 잘 뭉쳐져 있네요!

이런식으로 토픽을 하나씩 뽑아서 전체 키워드를 보실 수도 있습니다.

특정 단어와 가장 연관성이 높은 토픽을 찾는것도 가능합니다.

눈이 좀 아프지만 특정 토픽의 속한 문서 원문을 3개까지 볼 수도 있습니다.

사실 이렇게 62개까지 많은 토픽이 있지만... 다 보기가 힘들었습니다.
위의 파라미터 세팅이 주간 단위의 뉴스를 보는데 세팅해둔 것이라 작은 이슈들도 많이 생성된 것 같습니다.
작은 이슈들까지 모두 보고 싶다면 이렇게 하셔도 좋지만 나는 최소한의 토픽을 보고 싶다! 싶으시면
몇 가지 방법이 있습니다.
1. nr_topics = 'auto'
BERTopic()안에 nr_topics='auto'를 해주시면 비슷한 토픽끼리 묶어주기도 합니다.
하지만 연관성이 떨어지는 토픽도 한번에 묶어버려서 너무 적은 토픽이 생성될 수 있어 잘 사용하지는 않습니다.
2. 파라미터 세팅 변경

위의 BERTopic 세팅과 비교해보면 차이점이 보이실 겁니다.
n_neighbors를 늘리고 n_components는 줄였습니다.
hdbscan의 min_cluster_size가 사실 갯수를 줄이는데 한 몫하는데 저 값이 10이라면 아래의 34 토픽까지는 뽑히지 않을 것 입니다. 갯수가 적은 클러스터의 갯수는 제거하는 파라미터 입니다.
min_topic_size도 조절해줬는데 조절해줬을 시 토픽에 영향을 줍니다.
이렇게 세팅을 바꿔주고 결과를 보면 62개의 토픽에서 45개의 토픽으로 확 줄어든 것을 볼 수 있습니다.

3. hierarchical_topics

최근 새로 추가된 BERTopic의 hierarchical_topics를 사용해 비슷한 토픽을 직접 보고 묶어줄 수 있습니다.
BERTopic의 장점 중 하나인데 시각화가 참 좋아요... 다음과 같이 더 보기 쉽게 시각화도 가능합니다.

25번 토픽과 12번 토픽 대충봐도 비슷한 주제일 것 같죠? 두 토픽을 합쳐주도록 하겠습니다.

이렇게 합쳐주시면 25번 12번 토픽이 합쳐져서 새로운 3번토픽이 생성됐습니다.
두 토픽의 갯수가 합쳐져서 상위권 토픽으로 올라온 것으로 보입니다.

이런식으로 한번에 여러개도 묶어줄 수 있습니다.

-1로 분류된 문서들 마저도 버리기 싫다! 하시는 분들은 가장 연관있는 토픽으로 재분류도 가능합니다.
제가 기다리는게 귀찮아서 calculate_probablilities =False 하고 모델을 돌려버려서 필요하신분은 해보시면 될 것 같습니다.
BERTopic 시각화
앞서 언급했듯이 BERTopic의 장점은 시각화기능이 참 좋다는 것입니다.
Visualize_topics

visualize_barchart

visualize_heatmap

visualize_term_rank

요건 토픽 추세인데 이렇게 보면 보기가 힘들죠?
topics_over_time

이렇게 보면 일자별로 어떤 토픽이 증가하고 줄어들었는지 쉽게 보실 수 있습니다.
오른쪽 토픽을 리스트를 클릭하면 보기 싫은 추세선은 제거하고 다시 클릭하면 재생성 할 수 있습니다.
0번 토픽 전기차

전기차가 토픽 빈도가 어느 시점에 증가하는지 파악하실 수 있습니다.
마치며
BERTopic 관련 프로젝트를 하고 매번 쓰다보니까 BERTopic에 익숙해진 것 같습니다.
사실 더 많은 기능과 새로 추가된 기능들이 있는데 그거까지 다루면 스크롤이 너무 길어지고 제가 힘들거 같아서 여기까지
작성하도록 하겠습니다. 깃허브 링크를 달아둘테니 부족한 설명은 저기서 채우시면 될 것 같습니다.
https://maartengr.github.io/BERTopic/getting_started/quickstart/quickstart.html
Quickstart - BERTopic
Quickstart Installation Installation, with sentence-transformers, can be done using pypi: You may want to install more depending on the transformers and language backends that you will be using. The possible installations are: pip install bertopic[flair] p
maartengr.github.io
'Project' 카테고리의 다른 글
| [Project]한국 뉴스 감성분류, NER모델 Inference (0) | 2023.02.15 |
|---|---|
| [Project]한국 뉴스 NER 모델 개발 (feat. KCELECTRA) (0) | 2023.02.15 |
| [Project]한국 뉴스 토픽 모델링 (feat. KoBERTopic) (0) | 2023.02.14 |
| [Project]한국 경제 뉴스 기사 감정 분류 모델 개발 (feat.pytorch) (3) | 2023.01.20 |
| [Project]한국 광고 분류 모델 개발(1) (0) | 2022.12.30 |