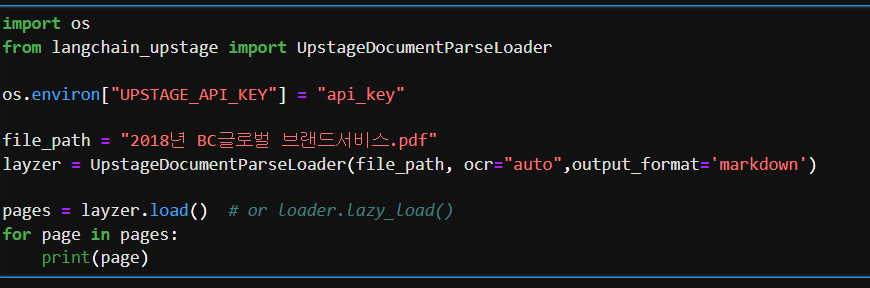
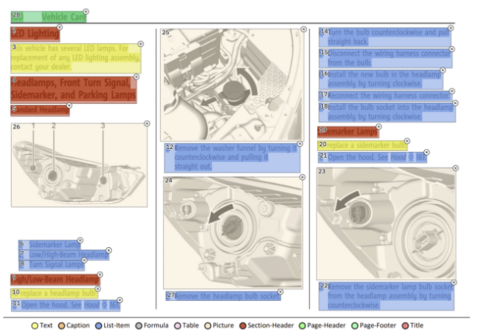
제가 예전에 작성한 글에 이번 글에서 언급되는 것들이 있어서 링크 함께 전달드리겠습니다. Document Layout Analysis 글https://mz-moonzoo.tistory.com/55 [Computer Vision] Document Layout Analysis (feat. OCR)1. Document Layout Analysis? 사람이 문서를 읽을 때에는 어떤 부분이 제목인지, 표는 어떻게 읽어야하는지, 이미지 아래에 작게 들어간 글자는 캡션이라고 이해하는 것 등 문서 내 정보에 대해 자연스mz-moonzoo.tistory.com PDFLoader 비교글https://mz-moonzoo.tistory.com/73 [RAG] Document Loader 비교 (feat. PDF, Markd..