INTRO
DACON에서 진행한 교원그룹 AI 챌린지
Task : OCR
평가지표 : Accuracy
처음으로 진행해보는 OCR Task라서 이것저것 찾아보면서 컴피티션을 진행했습니다.
TrOCR
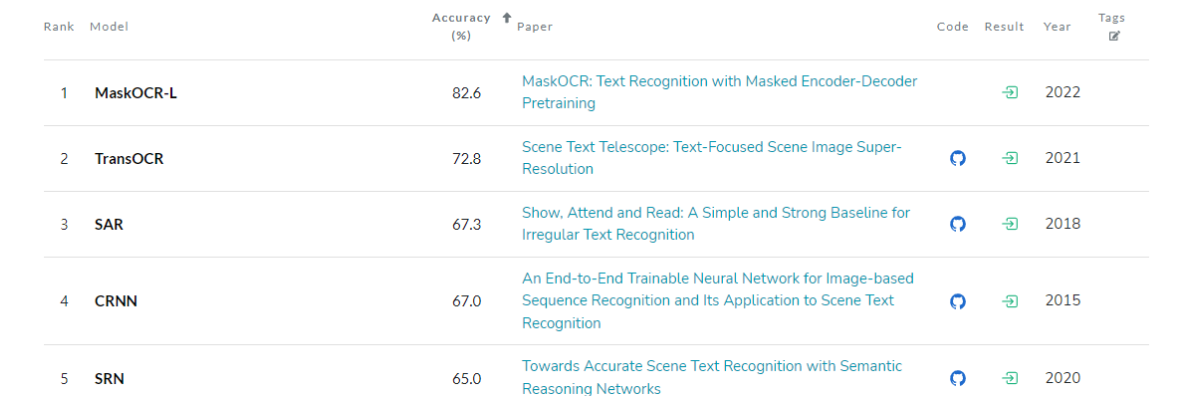
MaskOCR이 성능이 좋아보이지만 구현된 코드가 없어서 TrOCR을 사용해봤습니다.
TrOCR외에도 여러 모델을 사용해봤는데 이 글에서는 TrOCR 학습 과정에 대해 적어보려합니다.
1. 학습 환경 설정
깃허브 복제 및 라이브러리 설치

라이브러리 충돌이 나는 것을 방지하기 위해 아나콘다 가상환경을 새로 구축하고 실행했습니다.
우선 git clone을 통해 깃허브 리포지토리를 복제해 requirements를 설치 해주시면 됩니다.
패키지 불러오기

아래의 def 함수들은 실행하지 않으셔도 무방합니다. 가끔 에러가 나는 경우도 있어서...
혹시 에러가 나시는 분들은 제거하셔도 무방합니다.
모델 불러오기

대회 규칙에서 외부 데이터를 사용하면 안되기 때문에 한국어 외부 데이터셋으로 pretrained된 모델을 사용할 수 없습니다.
그렇기 때문에 위에서 FULL_TRAINING을 True 설정해줬습니다.
데이터셋 구축
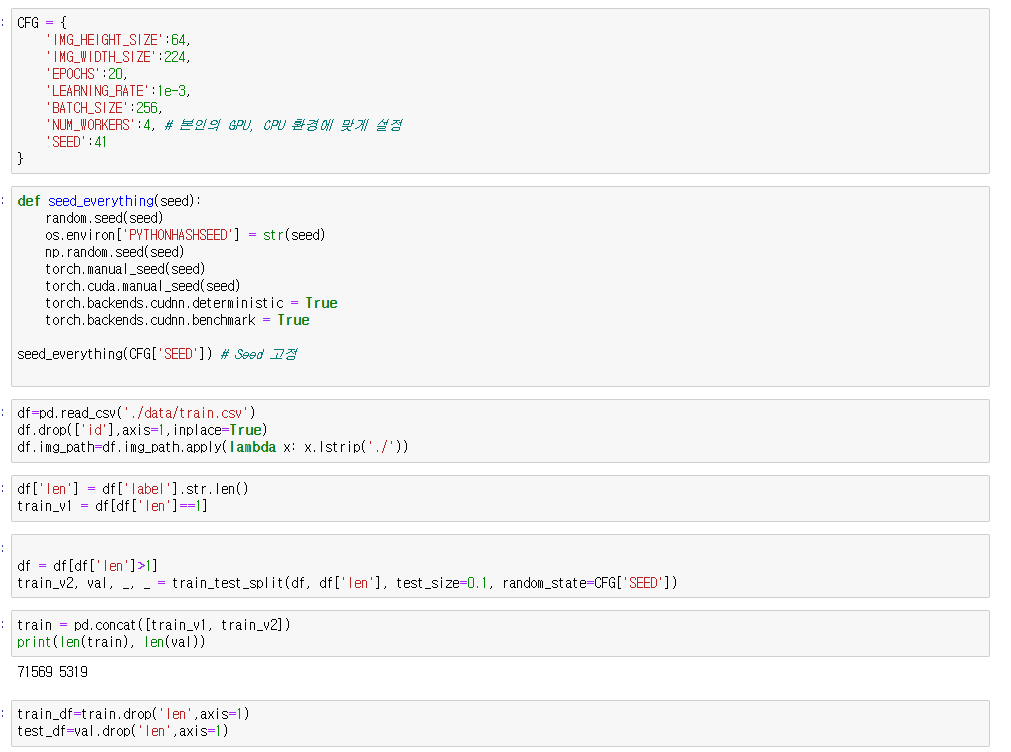
자신의 경로에서 학습 데이터의 img_path와 label이 있는 csv파일을 가져올 필요가 있습니다.
img_path를 수정해준 이유는 제가 데이터를 저장해둔 경로가 조금 달라서 수정해줬습니다.
각자 경로에 맞게 수정해주시면 될 것 같습니다.
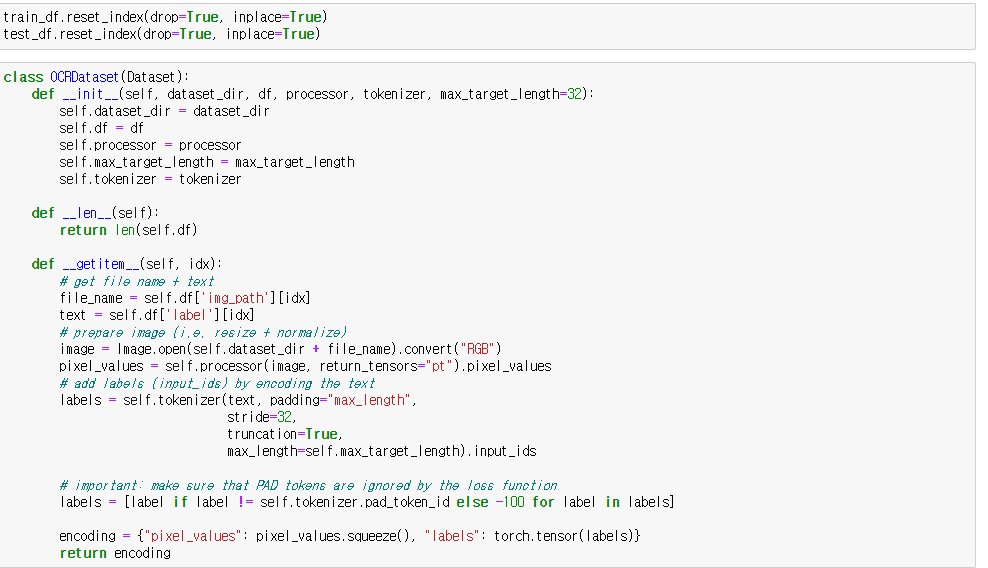
데이터셋 생성 함수입니다. 이부분은 딱히 설명할 내용은 없어서 넘어가도록 하겠습니다.
TrOCRProcessor에서 마이크로 소프트에서 공개한 손글씨 기반 pretrained 모델을 불러옵니다.
다음으로 max_length는 저희 학습 데이터와 테스트 데이터가 10글자가 넘지 않기 때문에 줄여주셔도 무방합니다.
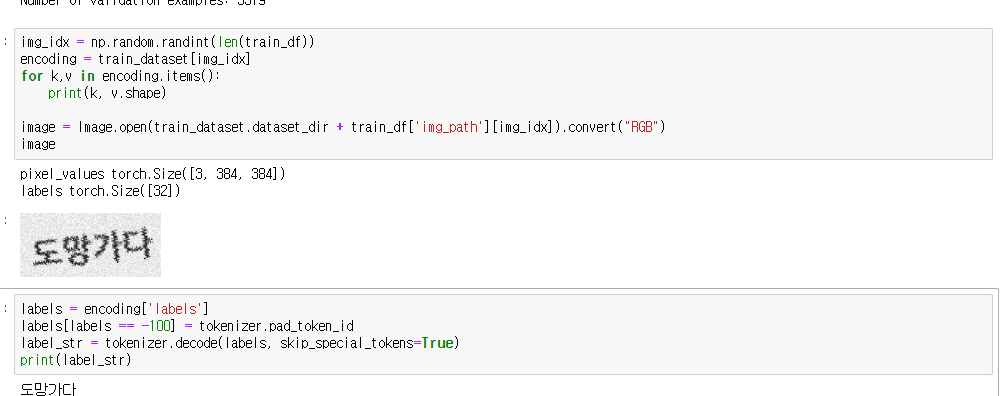
이제 준비가 거의 완료 됐습니다. 이미지를 잘 불러오는지 tokenzier 디코딩은 잘되는지 테스트 해보겠습니다.
이미지와 디코딩 역시 잘 되는 것을 확인했습니다.
2. 모델 학습
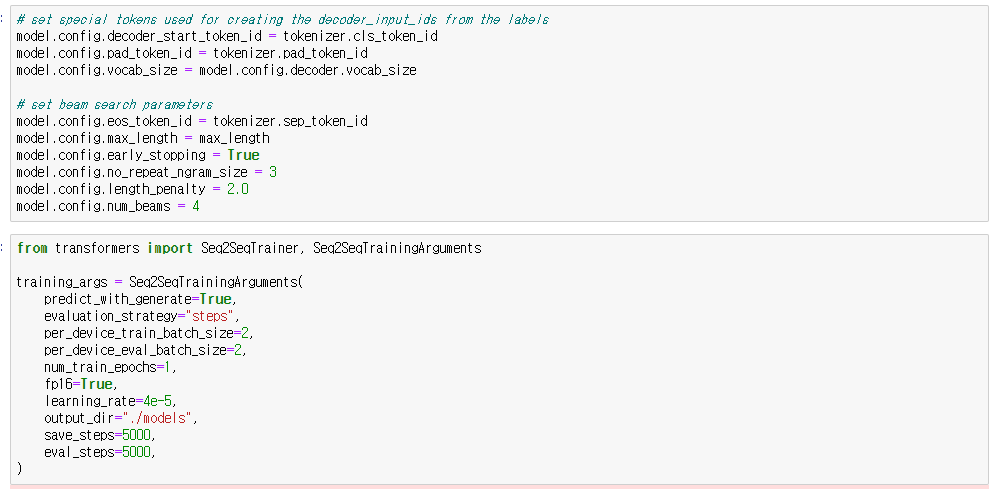
이제 모델 학습을 진행해보도록 하겠습니다. 우선 모델의 파라미터와 trainer 파라미터를 설정해주실 수 있습니다.
여기서 제가 수정한 부분은 per_device_train_batch_size와 per_device_eval_batch_size를 수정해줬습니다.
코랩이나 로컬에서는 gpu 메모리가 적어서 out of memory가 발생해서 배치 사이즈를 낮춰줬습니다.
num_train_epochs 역시 시간이 너무 오래걸려서 1~2로 설정해줬고 좋은 성능을 위해서는 epochs를 높이는게 좋습니다.
나머지는 딱히 건드리지 않고 바로 학습을 시작했습니다.
평가지표 설정
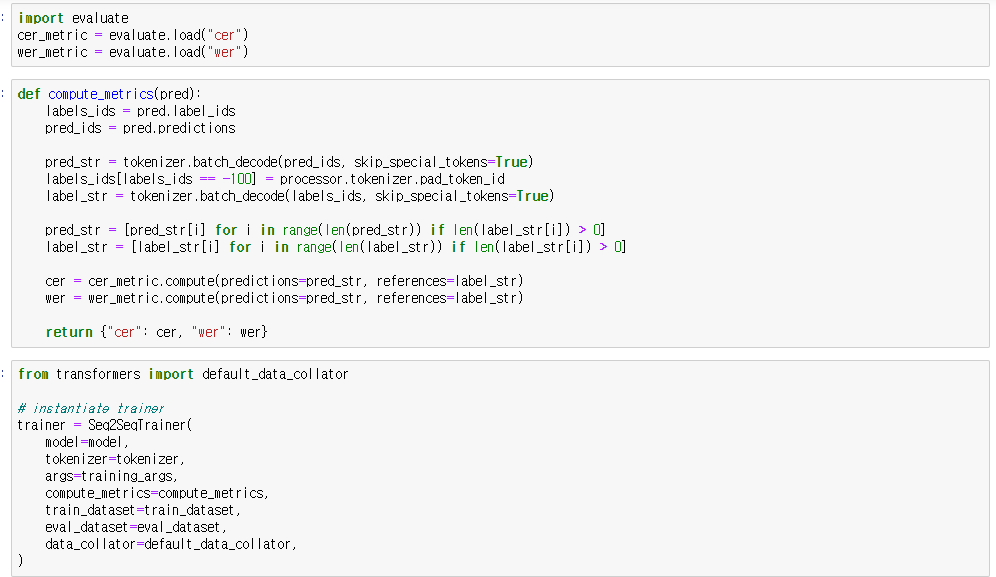
여기서 모델의 compute_metrics를 wer과 cer을 사용했는데 음성 인식 task에서 사용하는 평가지표입니다만
수정해주지 않아도 모델 학습이 진행됩니다. 이 부분은 custom metrics으로 수정해주셔도 좋을 것 같습니다.
① WER(Word Error Rate)
D : 인식된 텍스트에 잘못 삭제된 단어 수
S : 인식된 텍스트에 잘못 대체된 단어 수
I : 인식된 텍스트에 잘못 추가된 단어 수
N : 정답 텍스트의 단어 수
단어 에러 비율(WER) = (S+D+I)/N
② CER(Chatacter Error Rate)
D : 인식된 텍스트에 잘못 삭제된 음절 수
S : 인식된 텍스트에 잘못 대체된 음절 수
I : 인식된 텍스트에 잘못 추가된 음절 수
N : 정답 텍스트의 음절 수
음절 에러 비율(CER) = (S+D+I)/N
학습 시작
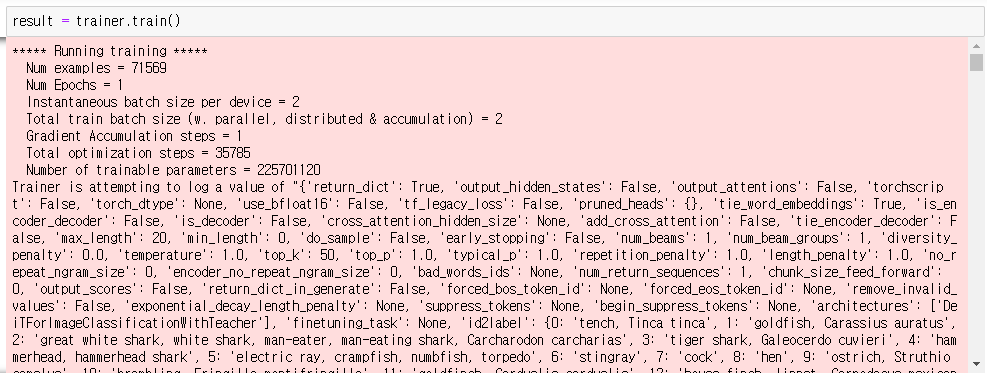
이제 trainer.train()을 통해 바로 모델 학습을 진행하도록 하겠습니다.
시간이 좀 걸려서 저는 2epochs까지 진행해봤습니다.
3. 추론
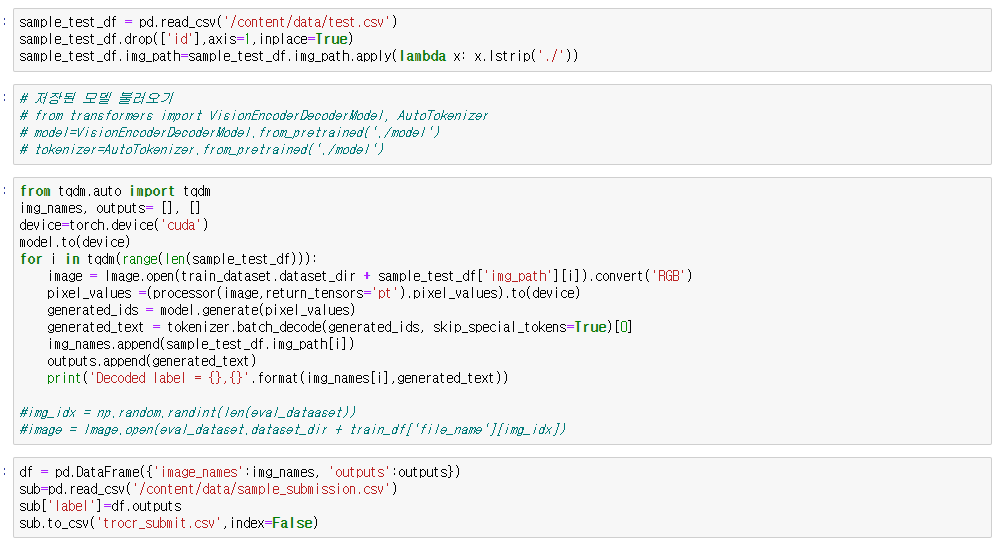
마지막으로 학습이 완료된 모델로 inference를 진행했습니다.
각자의 추론하고자 하는 img_path가 저장된 test.csv 파일을 불러오고 경로 수정을 해주시면 됩니다.
혹시나 세션을 닫아버려서 학습된 모델이 날라갔다면 미리 저장해둔 경로에서 모델을 불러오신다음 사용해주시면 됩니다.
결과적으로 2epochs밖에 진행하지 않고 Data Augementation도 진행하지 않은 상태여서 0.44의 성능이 나왔습니다.
하지만 오히려 2epochs에 0.44의 성능이 나온것이 생각보다 괜찮은 성능이라고 생각합니다.
저는 gpu살돈도.. 코플플 결제할 돈도 없어서 2epochs에서 멈췄지만 여유가 되시는 분들은 augmentation과 epochs를
늘려서 학습을 더 진행해보시면 좋을 것 같습니다.
전체 코드는 깃허브에서..
GitHub - moonjoo98/DACON: 2021~2022년에 참여한 DACON 공모전 정리입니다.
2021~2022년에 참여한 DACON 공모전 정리입니다. Contribute to moonjoo98/DACON development by creating an account on GitHub.
github.com