≒Paper: https://arxiv.org/abs/1703.10593
0. Abstarct
Image-to-image translation은 pair-image를 이용해 입력이미지와 출력 이미지 간의 매핑을 학습합니다.
그러나 많은 task의 경우 pair-image를 이루는 훈련 데이터를 구하기가 어렵습니다.
그래서 이 논문(Cycle-GAN)에서는 pair image를 이루는 데이터가 없을 때 원본 도메인 X에서 대상 도메인 Y로 이미지 번역하는 방법을 학습하는 방법을 제시합니다.
여러가지 이전 방법과 비교 해봤을 때, Cycle-GAN의 접근 방식은 우수성을 보여줍니다.
1. Introduction

pair-image를 이루는 훈련 데이터를 구하기가 어렵고 비용이 많이 들 수 있습니다.
논문에서는 pair image를 이루는 input-output 데이터가 없을 때 도메인 간 변환을 학습할 수 있는 알고리즘을 제안합니다.
여기서 저자는 학습을 위ㅐ서 도메인 사이에 기본 관계가 존재한다고 가정했습니다.
즉, input 와 output 가 의미 있는 방식으로 짝지어져야 한다는 것입니다. 쉽게 설명하자면
도메인 X로부터 Y로의 mapping을 G라 하고, G에 대한 네트워크를 학습시켰을 때 아래의 관계가 성립되어야 합니다.

위와 같이 G : X -> Y처럼 학습을 진행하면 input x에 해당하는 output y^가 도메인 Y에 속하는 이미지인 것처럼 학습할 수 있습니다. 최적의 G는 도메인 X를 Y와 동일하게 분포된 도메인 Y로 변환합니다.
그러나 x와 y^가 항상 의미 있는 방식으로 짝지어지지는 않습니다. G: X -> Y 입장에서는 단지 y^가 Y에 속하게끔 이미지를 변환하면 되기 때문에 즉, y^에 대해 동일한 분포를 유도하는 매핑 G가 무한히 많다는 것입니다.
더불어 실제로 adversarial objective를 단독으로 최적화하는 것이 어렵기 때문에 모든 입력 이미지가 동일한 출력 이미지에 매핑되고 최적화가 진행되지 않는 model collapse가 일어날 수 있습니다. (일반적인 GAN의 방식으로는 불가능)
이를 해결하기 위해 저자는 주기적 일관성(cycle consistent)이 있어야 한다는 속성을 이용했습니다.
예를 들어 문장을 영어에서 프랑스로 번역한 다음 프랑스어에서 영어로 다시 번역하면 원래 문장인 영어로 돌아가야 한다는 의미 입니다.
F(G(x)) ≈ x and G(F(y)) ≈ y
Cycle consistent 구조는 X to Y mapping을 G라하고, Y to X mapping를 F라 한다면 G와 F는 서로 bijection이 가능해야하는 구조 입니다. 저자는 이렇게 bijection이 가능한 G와 F의 관계로부터 계산되는 loss를 주기 일관성 손실(cycle-consistency loss)라 하며 이 손실을 일반적인 GAN의 loss와 결합하면 unpaired image-to-image translation에 대해 원하는 목표를 얻을 수 있다고 말했습니다.
2. Related work
생략
3. Formulation
논문의 목표는 두 도메인 를 잇는 mapping function을 학습시키는 것입니다.
3-1. Adversarial Loss
우리는 mapping function 두 개에 모두 adversarial loss를 적용했습니다.
G : X -> Y 및 판별자 D_y의 경우 다음과 같이 표현합니다.


여기서 G는 도메인 Y의 이미지와 유사한 이미지 G(x)를 생성하려고 하는 반면, Dy는 변환된 샘플 G(x)와 실제 샘플 y를
구별하려고 합니다. 즉, 와
거기에 adversarial discriminator 두 개를 가지고 있는데 는 image와 translated images를 구분하기 위한 것이고, 는 와 를 구분하기 위한 것입니다.
우선 왼쪽항부터 보게되면 G,DY,X,Y로 구성된 함수 LGAN이 있을 때 G는 LGAN의 값을 낮추려하고 DY는 LGAN의 값을 크게하고자 합니다.
오른쪽항을 보시면 우선 Generator는 두번째항에만 관여합니다.
Generator가 목표대로 잘 작동한다면 Discriminator가 진짜라고 속아 output이 1에 가깝게 나와 항이 작아져 LGAN값이 작아질 것입니다.
반대로 Discriminator가 목표대로 잘 작동한다면 Discriminator에 Y를 넣으면 Discriminator의 output이 1에 수렴하고 Y^을 넣었을 때는 0에 수렴해 LGAN값이 최대로 높아질 것입니다.
3-2. Cycle Consistency Loss
Adversarial training은 이론적으로 각각 목표 영역 Y와 X와 동일하게 분포된 출력을 생성하는 mapping G와 F를 학습할 수 있습니다.
하지만 large enough capacity라면, 네트워크는 한 이미지를 target domian에 있는 여러 이미지랑 mapping할 수 있습니다.
여기서 학습된 매핑은 대상 분포와 일치하는 출력 분포를 유도할 수 있습니다.
그러므로 Adversarial loss 하나로는 individual input 원하는 output 와 mapping 한다는 보장이 없습니다.
그렇기 때문에 가능한 mapping function의 공간을 줄이기 위해 학습된 매핑함수는 cycle-consistent이 있어야 합니다.

위 그림과 같이 도메인 X의 각 이미지 x에 대해 image translation cycle는 x를 원래 이미지로 되돌릴 수 있어야 합니다.
인 것을 볼 수 있는데, 이를 forward cycle consistency라 합니다.
도메인 Y,G 및 F의 각 이미지 y에 대해서도 backward cycle consistency이 충족해야 합니다.
식을 보면 y -> F(y) -> G(F(y)) ≈ y이고 cycle consistency loss를 사용하여 이 동작을 장려합니다.
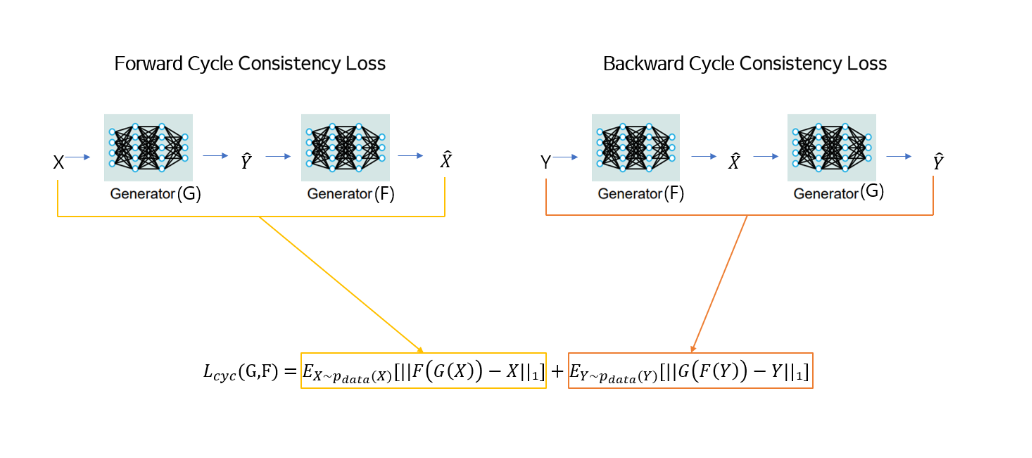
저자는 cycle consistency loss를 사용해 위와 같은 consistency를 만들도록 했습니다.
하지만 위 loss에 있는 L1 norm을 와 , 와 사이의 adversarial loss로 대체하려고 시도 했지만, 개선된 성능을 관찰하지는 못했습니다. cycle consistency loss에 의해 유도된 동작은 위의 그림(2)에서 관찰 할 수 있습니다.
재 구성된 이미지 F(G(x))는 입력 이미지 x와 밀접하게 일치하게 됩니다.
3.3 Full Objective
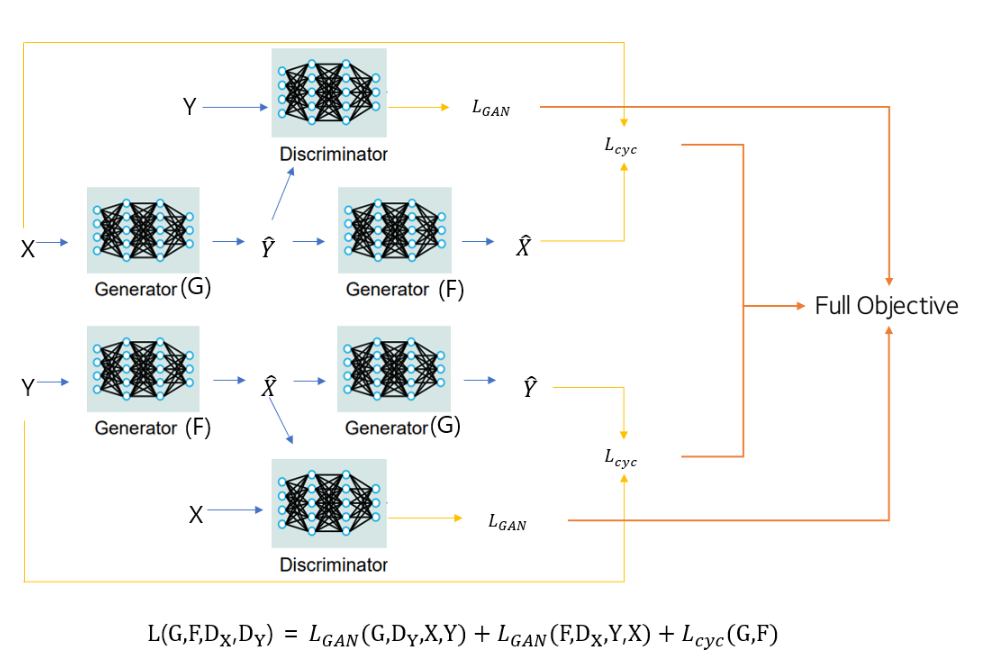
저자의 완전한 목표는 위의 식과 같습니다.
여기서 는 두 objective 사이의 relative importance를 조절합니다
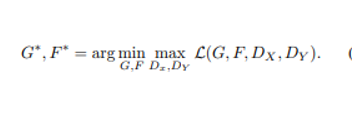
.그리고 저자는 위의 식을 해결하는 것을 목표로 합니다. 두 식과 모델의 구조를 보면 두 개의 'autoencoder'를 훈련하는 것으로 볼 수 있습니다. 하나의 autoencoder F ° G : X →X를 다른 G ° F : Y→ Y와 함께 학습합니다. 하지만 이러한 autoencoder에는 특별한 내부 구조를 가지고 있습니다. 이미지를 다른 도메인으로 변환하는 intermediate representation을 통해 이미지를 자체적으로 매핑 합니다. 이 논문의 경우 X -> X 오토인코더의 대상 분포는 도메인 Y의 분포입니다.
정리하자면 두 개의 Generator의 output들을 Discriminator에 입력으로 해 각각의 손실을 얻고, 주기일관성 손실을 얻기위해 앞에 학습한 서로의 Generator를 가져옵니다. 그 후 다시 원본 분포에 가깝게 만든 output들로 주기일관성 손실을 계산하는 것입니다.
4. Implementation
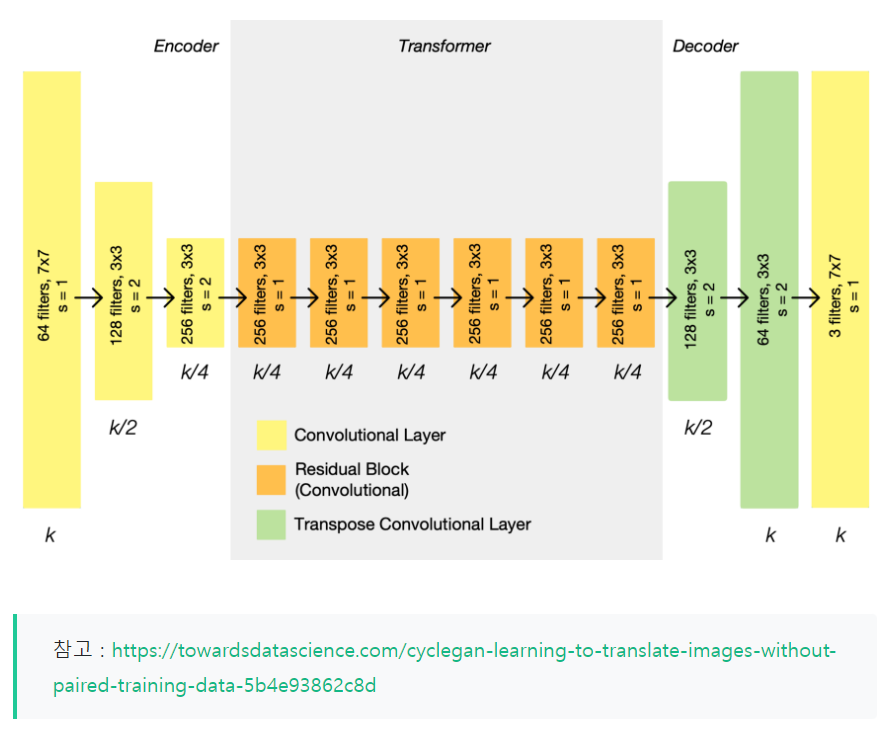
4-1. CycleGAN Generator Architecture
인코더 , 변환기 및 디코더 의 세 부분으로 구성 됩니다. 입력 이미지는 인코더에 직접 입력되어 채널 수를 늘리는 동안 representation size를 줄입니다. 인코더는 3개의 컨볼루션 레이어로 구성됩니다.
할성화된 결과는 일련의 6개의 잔차 블록인 변환기로 전달됩니다.
그런 다음 디코더에 의해 다시 확장되며, 두 개의 transpose 컨볼루션을 사용하여 representation size를 확대하고 하나의 출력 레이어를 사용하여 최종 이미지를 RGB로 생성합니다.
그림을 보면 쉽게 이해하실 수 있습니다.
그림에서는 각 레이어 뒤에는 instance normalization 과 ReLU 레이어가 있지만 단순성을 위해 생략되었습니다.
제너레이터의 아키텍처는 fully convolutional이기 때문에 일단 훈련되면 임의의 큰 입력을 처리할 수 있습니다.
4-2. CycleGAN Discriminator Architecture
Discriminator는 입력 이미지의 "patch"를 확인하고 패치가 "real"일 확률을 출력하는 fully convolutional neural networks인 PatchGAN입니다. 이것은 전체 입력 이미지를 보려고 시도하는 것보다 계산적으로 더 효율적이고 더 효과적입니다.
판별자가 텍스처와 같은 더 많은 surface-level features에 집중할 수 있습니다.
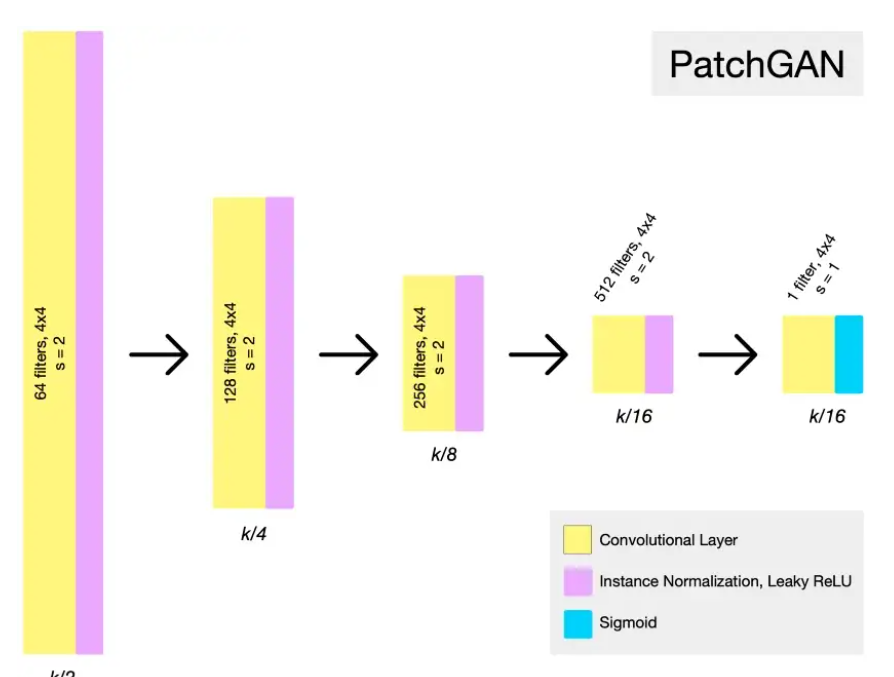
위의 예제 아키텍처에서 볼 수 있듯이 PatchGAN은 원하는 출력 크기에 도달할 때까지 representation size를 절반으로 줄이고 채널 수를 두 배로 늘립니다. 이 경우 PatchGAN이 입력의 70x70 크기 패치를 평가하도록 하는 것이 가장 효과적이었습니다.
4.3 Training Details
저자들은 모델 학습을 안정화시키기 위해 아래와 같은 테크닉을 추가로 적용합니다.
- 의 nll loss를 least-squared loss로 변경.
- 생성된 이미지 중 가장 최근의 50개를 따로 저장해 Discriminator가 이를 한꺼번에 분류(모델 진동 최소화).
- 모든 실험에 대해 λ = 10을 설정. batch size = 1, optimizer = Adam, lr = 0.0002
모델이 반복마다 크게 변경되는 것을 방지하기 위해 최신 버전의 Generator가 생성한 이미지가 아니라 생성된 이미지 의 history를 Discriminator에게 제공했습니다. 이를 위해 가장 최근에 생성된 50개의 이미지를 저장하는 이미지 버퍼를 유지합니다
모델 진동을 줄이기 위해 최근 생성 이미지를 한 꺼번에 분류하는 건 직관적으로 와닿을 것입니다.
분류기에 왜 Least-sqaure loss를 사용할까요?
한 마디로 Generator의 업데이트를 위해서입니다.
이에 대한 내용은 LSGAN을 참고하면 됩니다.
여기서는 간단히만 살펴보겠습니다.
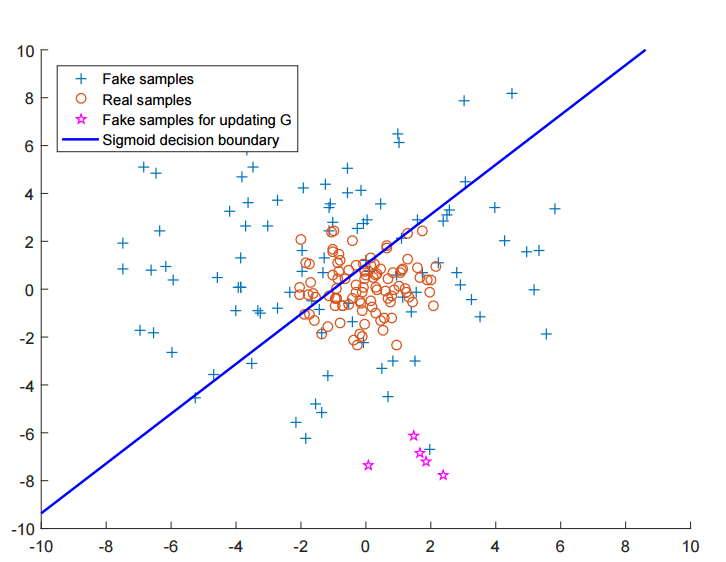
(원래 Discriminator는 이보다 더 고차원이지만) 간략히 2차원을 표방하면 결정경계를 위와 같이 나타낼 수 있습니다.
- 윗 쪽이 가짜 영역, 아래 쪽이 진짜 영역입니다
이 때, 아래에 보면 진짜 데이터 샘플과 거리가 먼 가짜 데이터 샘플이 존재합니다.
즉, Generator의 입장에서는 이미 Discriminator를 잘 속이고 있기 때문에 학습할 필요가 없습니다.
NLL Loss를 사용한다면요.
즉, Vanishing Gradient가 일어나기 때문에, Discriminator를 잘 속인다는 이유만으로, 안 좋은 샘플을 생성하는 것에 대해 패널티를 줄 수가 없게 됩니다.
이 때, LS GAN을 사용한다면 실제 데이터 분포와 가짜 데이터 샘플이 거리가 먼 것에 대해서도 패널티를 주게 됩니다.
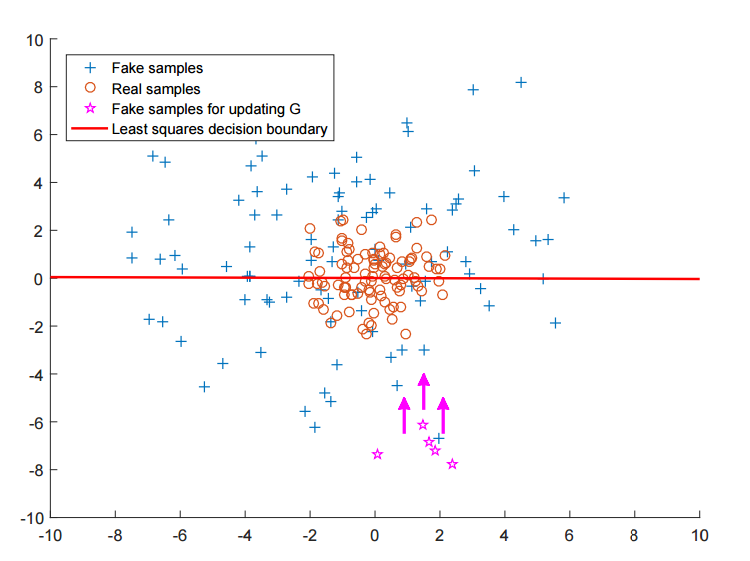
Generator는 Discriminator를 속이는 것을 넘어서, 실제 데이터 분포와 유사한 분포를 가지게끔 해야합니다.
5. Evaluation Metrics
1. human study(정성적)
-> 참가자들에게 실제 사진 또는 진짜와 가짜로 구성된 일련의 이미지 쌍을 보여주고 실제라고 생각하는 이미지를 클릭하 도록 요청했습니다.
2. FCN Score(정량적)
-> FCN 메트릭은 off-the-shelf semantic segmentation algorithm의 ([33]의 fully-convolutional network, FCN)에 따라 생성 된 사진이 얼마나 해석 가능한지 평가합니다.
도로 위의 자동차"라는 레이블 맵에서 사진을 생성하면 생성된 사진에 적용된 FCN이 "도로 위의 자동차"를 감지하면 성 공한 것입니다.
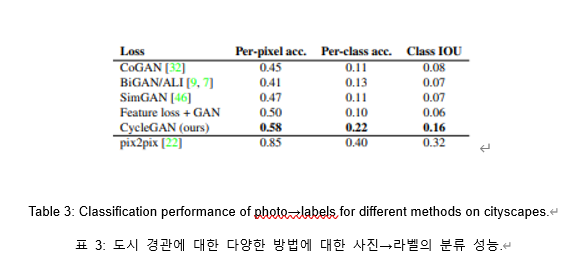
3. 사진을 라벨링하는 성능을 평가하기 위해 per-pixel accuracy, IoU사용.
compare scores
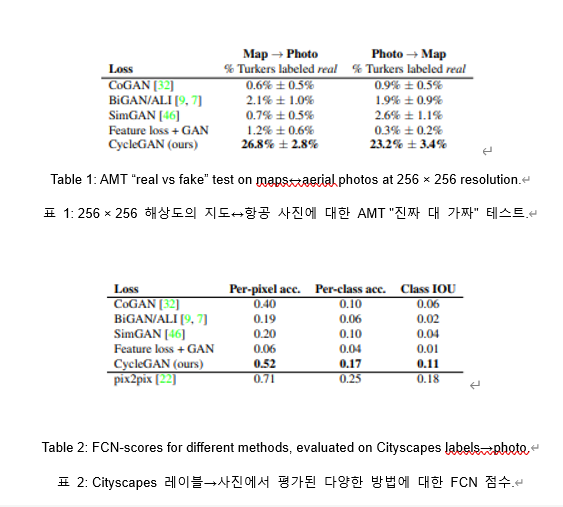
Different methods for mapping aerial photos

Application

L_identity가 없으면 생성기 G와 F는 필요하지 않을 때 입력 이미지의 색조를 자유롭게 변경할 수 있습니다.
예를 들어, Monet의 그림과 Flickr 사진 간의 매핑을 학습할 때 Generator는 종종 낮의 그림을 일몰 동안 찍은 사진에 매핑합니다. 이러한 매핑은 적대적 손실과 주기 일관성 손실에서 동일하게 유효할 수 있기 때문입니다.
즉, 인풋과 아웃풋의 색구성을 보존하기 위해 추가한 loss입니다.
그림 9 에서는 해가뜨는 것과 해가 저무는 것을 구분하기 위한 loss입니다.
6. Limitations
우리의 방법은 많은 경우에 매력적인 결과를 얻을 수 있지만 결과는 모든 케이스에서 긍정적이지는 않습니다.

위의 그림 17(Figure. 17)을 보면 나쁜 결과들의 예시를 볼 수 있습니다.
몇몇 실패 사례는 training dataset에서의 특성에 있습니다.
예를 들어, 위의 말을 얼룩말로 바꾸는 사례를 보면 얼룩말을 탄 사람 이미지는 없기 떄문에 성능이 좋지 않습니다.
cat-dog 사례를 봐도 모양은 바꿀 수 없다는 것을 확인할 수 있습니다.
Ref