이번에 소개할 논문은 A Style-Based Generator Architecture for Generative Adversarial Networks으로 StyleGAN으로 자연스러운 고해상도 이미지를 만들면서 많이 알려지게 된 논문입니다. 저희 학회 컨퍼런스에서 함께 진행한 논문 스터디이기 때문에 팀원인 https://rahites.tistory.com/85?category=1083611의 글에서 조금 수정해서 작성하도록 하겠습니다.
StyleGAN
( A Style-Based Generator Architecture for Generative Adversarial Networks )
Abstract
[제안한 네트워크]
StyleGAN은 기존의 PGGAN 구조에 Style transfer 개념을 적용하여 generator architecture를 재구성한 아키텍처
[새로운 데이터셋 제공]
본 논문에서는 새로운 아키텍처와 함께 매우 다양하고 고품질의 human faces data set을 소개한다.
Introduction
최근 GAN을 기반으로 한 이미지 합성 기술은 PGGAN 등을 포함하여 빠르게 개선되고 있습니다. 그러나 Generator를 통한 이미지 합성 과정은 여전히 block box로 여겨지며 최근에 노력에도 불구하고 stochastic features과 같은 합성 과정의 다양한 측면에 대한 이해가 여전히 부족합니다. latent space의 속성도 제대로 이해되지 않고 있으며, 일반적으로 입증된 latent space interpolations은 서로 다른 generator를 비교할 수 있는 정량적 방법을 제공하지 않습니다. 쉽게 예를 들자면, 합성되는 이미지의 attribute (성별, 연령, 헤어스타일 등) 을 조절하기가 매우 어렵다는 한계가 있다는 것입니다. StyleGAN은 이러한 문제를 해결하기위해 Style Transfer에 기반한 새로운 generator 구조와 기존의 고해상도 데이터 세트보다 훨씬 더 높은 품질을 제공하고 훨씬 더 넓은 변형을 포함하는 새로운 human face 데이터셋을 제안했습니다.
< 본 개념을 이해하기 위해 필요한 지식 >
PGGAN ( Progressive Growing of GANs ) (2018)
- 일반적인 GAN을 이용해 고해상도 이미지를 만들면 해상도(Resolution)가 높아질수록 Discriminator가 Generator가 생성한 Image의 Fake 여부를 판단하기 쉬워집니다. 또한 고해상도 이미지를 만들었더라도 메모리 제약 때문에 mini batch size를 줄여야하고 batch size를 줄일경우 학습과정에서 학습이 불안정해지는 문제가 발생합니다.
- 따라서 PGGAN의 핵심은 layer(Generator와 Discriminator)를 점진적으로 추가해주어 낮은 해상도를 높은 해상도로 만들어주는 것입니다. 즉, Generator와 Discriminator를 낮은 해상도의 이미지에서 시작하여 점점 높은 해상도의 이미지를 학습해가게 만든다는 것을 의미합니다. 이 때 layer를 점진적으로 추가해주면 Image Distribution에서 Large Scale(큰 구조)를 먼저 발견할 수 있게 만들고 처음에 낮은 해상도에서 학습을 할 때에는 Large Scale을 보며 전반적인 내용을 학습하고, layer를 쌓아 학습을 진행하면서 세부적인 Feature들을 보며 학습을 진행합니다. 이는 안정적인 학습을 가능케 합니다. 새로운 layer를 추가할 때는 smooth하게 fade in을 진행해 줍니다. smooth fade in 은 이미 잘 학습된 이전 단계의 layer에 영향을 미치지 않도록 이전에 학습된 layer의 출력물과 새로운 이미지를 합치는 방식을 말합니다. 이는 기존의 저해상도 layer에서 학습된 방향에 영향을 미치지 않고 새로운 layer를 학습시킬 수 있습니다.

PGGAN의 구조
- GAN에서는 공변량 변화(Convariate Shift, 학습하는 도중에 이전 layer의 파라미터 변화로 인해 현재 layer의 입력의 분포가 바뀌는 현상)를 억제하기 위한 Batch Normalization 방법이 사용되었지만 PGGAN에서는 발생하지 않기 때문에 Batch Normalization을 사용하지 않았습니다. 대신 Pixelwise Normalization을 사용했는데, 이는 pixel마다 존재하는 Feature Vector를 단위 길이별로 Normalization해주는 것을 말합니다. Pixelwise Normalization은 train 과정에서 신호의 크기가 제어를 벗어나는 것을 효과적으로 방지해줍니다.
class PixelNormLayer(nn.Module) :
def __init__(self) :
super(PixelNormLayer, self).__init()
def forward(self, x) :
return x * torch.rsqrt(torch.mean(x ** 2, dim = 1, keepdim = True) + 1e-8)
def __repr__(self) :
return self.__class__.__name__
DCGAN(2016)
Convolutional Filter
- Discriminator는 안쪽 layer로 들어가면서 너비와 높이가 감소하고 채널이 증가 (DownSampling-Strided Convolution)
- Generator는 안쪽 layer로 들어가면서 너비와 높이가 증가하고 채널은 감소 (UpSampling-Transposed Convolution)
Vector Arithmetic
latent vector끼리의 연산으로 원하는 생성 이미지를 만들 수 있다
[ Man with glasses - Man without glasses + woman without glasses = woman with glasses ]
StyleGAN( A Style-Based Generator Architecture for Generative Adversarial Networks )
StyleGAN은 기존의 PGGAN 구조에 Style transfer 개념을 적용하여 generator architecture를 재구성한 아키텍처입니다.
본 논문에서는 새로운 아키텍처와 함께 새로운 hunam faces data set을 소개합니다.
StyleGAN의 아이디어는 마치 디자이너가 로고색만 다른 색으로 색칠하고, 배경색만 다른 색으로 색칠하는 것 처럼 기존의 PGGAN에서도 style들을 변형시키고 싶은데 PGGAN에서는 latent vector z가 모델에 바로 입력되기 때문에 latent space가 train data set의 확률분포의 비슷한 형태로 만들어져 만들어진 latent space가 Entangle하게 되어 불가능하다는 단점이 있습니다.
Entangle이란 여러가지 특성이 엉켜있어 특징을 구분하기 어려운 상태를 말하고,
Disentangle이란 각 style(특징)이 잘 구분되어 있어 선형적으로 변수를 변경했을 때 어떤 결과물의 feature인지 예측할 수 있는 상태를 의미합니다.

기존의 방법에서처럼 input vector로부터 이미지를 직접 생성할 경우, 위의 그림(a)를 보면 고정된 input distribution에 학습 이미지의 distribution을 맞춰야합니다. 하지만 training data의 단순 확률분포에서 왼쪽 위의 영역에 들어가야하는 요인의 조합이 존재하지 않을 경우, 해당 요인의 조합이 없는 채 억지로 mapping을 진행한 그림(b)와 같은 visual atrtribute가 input space에 non-linear하게 mappnig되고, input vecotr로 visual attribute를 조절하기 어려워지고 latent space Z에서는 wrapping이 발생합니다. wrapping이 발생하면 생성된 이미지의 형태가 어떻게 생성될지 모를정도로 급진적인 변화가 일어납니다. 예를들어, 학습 이미지에 검은 머리의 사람이 대부분일 경우, input space의 대부분의 영역이 검은 머리를 표현하게되고, input vector를 조절하여 머리색을 변경하기가 어려워집니다. 그러나 그림 (c)처럼 mapping netowrk를 사용할 경우 w는 고정된 distribution을 따를 필요가 없어지기 때문에, 학습 데이터를 헐씬 intermediate leatent space에 mapping할 수 있고 w를 이용하여 visual attribute를 조절하기가 훨씬 용이해집니다.
이러한 문제를 극복하기 위해 StyleGAN에서는 Style Transfer처럼 원하는 style로 수치화 시킨 후 각기 다른 style을 여러 scale에 넣어 GAN에 적용하고자 했습니다. 이 때 latent variable 기반의 생성 모델이 가우시안 분포 형태의 random noise를 입력으로 넣어주기 때문에 latent space가 Entangled하다는 문제를 GAN모델에 넣기 전에 먼저 latent vector z가 학습 데이터 셋과 비슷한 확률 분포를 갖도록 non-linear하게 mapping하는 것으로 극복하였습니다.
기존의 방식은 input vector에서 이미지를 직접 생성할 경우 input distribution에 학습 이미지의 distribution을 맞춰야하지만, 그림 (c)처럼 mapping netowrk를 사용할 경우 w는 고정된 distribution을 따를 필요가 없어지기 때문에, 학습 데이터를 훨씬 intermediate leatent space에 mapping할 수 있고 w를 이용하여 visual attribute를 조절하기가 훨씬 용이해집니다. 그 결과 Mapping Network를 거쳐서 나온 w는 Disentangle하다는 특징을 가집니다. ( 그림(b)보다 선들이 linear함, 경험적으로 w의 성능이 좋음 )
* Mapping Network
: 특정 Space에서의 Vector를 다른 Space의 Vector로 매핑해주는 것
Latent vector z(차원이 줄어든 채로 데이터를 잘 설명할 수 있는 잠재 공간에서의 벡터)를 가우시안 분포를 통해 뽑은 뒤 바로 사용하지 않고 별도의 Mapping Network를 거쳐 Latent vector w로 변환한 뒤 이미지를 만든 후 해당 space에서 interpolation을 진행하면 더 linear한 space를 따라갈 수 있다.
* AdaIN (Adaptive Instance Normalization)
ADaIN이라는 Layer를 활용해 style 정보를 입힐 수 있도록 만들었습니다. 하나의 이미지를 생성할 때 여러개의 스타일 정보가 레이어를 거칠 때마다 입혀질 수 있도록 하기 위해 AdaIN을 사용했습니다. AdaIN을 이용해 다른 원하는 데이터로부터 스타일 정보를 가져와 적용할 수 있고, 이는 feed-forward 방식의 style transfer 네트워크에서 주로 사용되어 좋은 성능을 보인 방식입니다.
- 학습시킬 파라미터가 필요 X
- 정규화를 수행한 뒤 입력받은 스타일 정보를 입력 받아서 feature 상의 statistics를 바꾸는 방식으로 style을 입히는 것이 Adaptie Instance Normalization입니다.
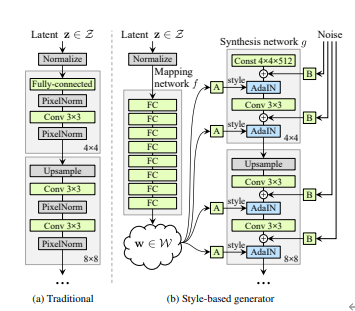
앞서 설명한 Style Module 즉 AdaIN Layer은 위 같은 방식으로 들어가게 됩니다. 각 convolution layer 이후마다 AdaIN을 통해 style이 입혀집니다. 이러한 구조는 Synthesis network의 매 layer마다 AdaIN을 통해 style normalize한 후 새로운 style을 입히게 되므로, 특정 layer에 입혀진 style은 바로 다음 convolutional layer에만 영향을 끼칩니다. 따라서 각 layer의 style이 특정한 visual attribute만 담당하는 것이 쉬워집니다.
* Stochastic Variation
위 그림의 우측 끝에 Noise 부분을 보면 알수 있듯이 다양하게 발생할 수 있는 확률적인 측면도 처리할 수 있도록 구성하였습니다. ( 주근깨, 머리카락의 배치 등 ) StyleGAN에서는 이를 표현하기 위해 synthesis netowrk의 각 layer마다 random noise를 추가하였고, 이렇게 stochastic한 정보를 따로 추가해주면 더욱 사실적인 이미지를 생성하게 될 뿐 아니라, input latent vector는 이미지의 중요한 정보를 표현하는데에만 집중할 수 있게되고 조절하는 것 역시 더 쉬워집니다.
* 별도의 Noise input을 넣어 이를 가능케 했고 Noise 역시 Affine 변환을 거친 후 network에 포함됩니다.

(a)는 모든 레이어에 노이즈 적용 (b) 노이즈 적용 x, (c) Fine layer에 노이즈 적용, (d) Coarse layer에 노이즈 적용
더 큰 규모의 stochastic한 정보들이 표현된 것 을 알 수 있습니다.
논문에서는 각각의 style 정보가 입력되는 위치에 따라 해당 style에 미치는 규모가 달라질 수 있다고 언급했습니다.
Coarse style : 세밀하지는 않지만 전반적인 semantic feature들을 바꿀 수 있는 style ( Latent Vector w의 앞쪽 1~4 layer)
Middle style : 헤어스타일, 눈을 감은 여부 등 조금 더 세밀한 style ( Latent Vector w의 앞쪽 5~8 layer)
Fine style : 색상, 미세한 구조와 같이 더 세밀한 style ( Latent Vector w의 앞쪽 9~18 layer)
* Style mixing
Mapping network로부터 나온 intermediate vector w는 synthesis netowr의 모든 layer에 대한 style를 표현하도록 학습되는데, 이는 여러 layer에 대한 style이 correlate되는 위험을 발생시킬 수 있습니다. 이를 해결 하기위해 style mixing를 제안했습니다. 스타일의 localize를 더욱 장려하기 위해 mixing 정규화를 사용합니다. 주어진 비율의 이미지는 훈련 중에 하나가 아닌 두개의 임의의 latent code를 사용하여 생성됩니다. 즉 두개의 input vecotr로부터 w1,w2를 만들어내고 synthesis network 초반에는 w1로 학습하다가 특정 layer 이후부터는 w2를 적용하여 학습합니다. 이 때 style이 교체되는 layer를 매번 random하게 결정해줌으로써 연속된 두 layer간의 style의 correlate 되는 현상을 방지할 수 있습니다. 이렇게 학습된 모델은 각 layer가 담당하는 style이 뚜렷하게 구분되는 것을 확인할 수 있습니다.
Conclusion
이 논문은 이미지 합성을 위해 새로운 generator 구조를 제시하였고, 기존의 GAN generator 아키텍처가 모든 면에서 style-base design(새로운 generator)보다 열등하다는 것이 분명해지고 있습니다. 새로운 generator은 합성되는 이미지의 구성요소를 조정하는 것 역시 가능해지며 나아가 CNN에 다양한 visual attribute를 어떻게 encoding 하는지에 대한 이해도 증가에도 기여했습니다. 이 논문에서는 generator 구조에만 집중하였기 때문에 dicsriminator 구조나 loss function등의 변경을 통해 더욱 개선될 여지도 보여집니다.
<요약>

1. Mapping Network에서 Latent Vector w를 뽑는다.
2. w를 별도의 Affine 변환을 거쳐 AdaIN에 들어가는 style 정보가 될 수 있도록 만든다.
3. 생성 네트워크는 저해상도부터 시작해 점차 너비와 높이를 증가시키는(해상도를 높이는) 방향으로 구성된다. (9개의 block)
4. 각각의 block은 2개의 Convolution layer와 2개의 AdaIN layer를 가진다.
5. Convolution layer에는 너비와 높이를 증가시키기 위한 Upsampling layer가 포함된다.
< 참고자료 >
https://blog.promedius.ai/stylegan_1/
https://airsbigdata.tistory.com/217
https://wiserloner.tistory.com/1196