1. Document Layout Analysis?
사람이 문서를 읽을 때에는 어떤 부분이 제목인지, 표는 어떻게 읽어야하는지, 이미지 아래에 작게 들어간 글자는 캡션이라고 이해하는 것 등 문서 내 정보에 대해 자연스럽게 인식할 수 있습니다. 하지만 OCR 기술은 단순히 글자만 인식할 뿐, 문서에 대해 자동으로 이해하고 각 글자들이 어떤 맥락에서 배치되어 있는지는 전혀 읽어내지 못합니다.
그래서 등장한 것이 Document Layout Analysis 기술입니다. 컴퓨터 비전(CV) 또는 자연어 처리(NLP)에서 사용하는 기술로, 주로 텍스트 문서내에서 관심 영역을 식별하고 분류하는 기술입니다. 이 기술은 문서의 레이아웃을 분석하여 텍스트, 이미지, 표, 그래프 등 다양한 요소를 구분하고, 이러한 요소들의 위치, 크기, 관계 등을 파악합니다.
Layout analysis는 OCR (Optical Character Recognition) 시스템의 전처리 단계에서 중요한 역할을 하며, 일반적으로 문서 이미지가 OCR 모델에 Input 되기 전에 수행됩니다. 또한, 대용량의 이미지 데이터 속에서 중복된 이미지를 검색하거나, 구조 또는 그림 내용을 기준으로 문서를 색인화하는 데에도 사용됩니다. 주요 기능은 다음과 같습니다.
- 텍스트 및 비텍스트 요소 인식: 문서에서 텍스트, 이미지, 표, 그래픽 등의 요소를 식별합니다.
- 텍스트 블록 분할: 페이지 내의 텍스트를 의미 있는 단위로 구분합니다. 이는 텍스트의 논리적 흐름을 파악하는 데 도움이 됩니다.
- 페이지 레이아웃 구조 분석: 문서의 레이아웃을 분석하여 헤더, 푸터, 마진, 칼럼 등의 구조적 요소를 식별합니다.
- 문서 유형 분류: 레이아웃 정보를 사용하여 문서를 분류하고, 특정 형식(예: 세부산정내역서, 진단서 등)의 문서를 식별합니다.
레이아웃 분류 예시
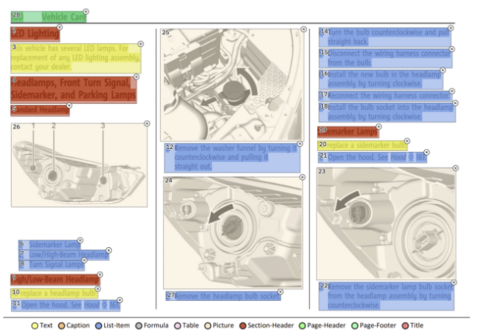
위의 이미지는 Document Layout Analysis Task의 학습 데이터셋 중 하나인 DocLayNet입니다. 영어로 된 6가지 문서 유형의 80,863 문서 레이아웃 분할 데이터셋으로, 라벨링을 하는 사람의 인식과 해석이 레이아웃 분할의 기준이 되었습니다.
페이지의 제목(Page-Header) : Vehicle Care
섹션의 제목(Section-Header) : LED Lighting
텍스트(Text) : replace a headlamp…
이와 같이 문서 내에서 레이아웃을 분류합니다.
2. Document Layout Analysis VS Optical Character Recognition
그렇다면 Document Layout Analysis (DLA) 기술과 Optical Character Recognition (OCR)의 차이는 무엇일까요?
Optical Character Recognition (OCR)
- 목적: OCR의 주된 목적은 이미지에서 텍스트를 인식하고 디지털 텍스트로 변환하는 것입니다. 이 과정은 스캔된 문서, 사진 속의 글자, PDF 파일 등에서 문자를 읽어내는 데 초점을 맞춥니다.
- 기능: OCR은 문자 인식에 특화되어 있으며, 주로 텍스트 추출을 위해 사용됩니다. 이 기술은 텍스트의 실제 내용을 디코딩하여, 컴퓨터가 이해할 수 있는 형식으로 변환합니다.
Document Layout Analysis (DLA)
- 목적: Layout Analysis는 문서의 물리적 구조와 배치를 이해하고 분석하는 것을 목적으로 합니다. 이는 문서 내의 텍스트와 비텍스트 요소(예: 이미지, 표, 그래프)의 위치, 크기, 그리고 서로 간의 관계를 식별하는 데 중점을 둡니다.
- 기능: 이 기술은 문서의 레이아웃과 구조를 파악하여, 문서의 논리적 구성을 이해하고, 텍스트 블록을 의미 있는 단위로 구분하는 데 사용됩니다. 또한, 문서의 다양한 섹션을 식별하고, 텍스트와 비텍스트 요소를 구별합니다.
OCR과 Layout Analysis의 차이점
- 작업의 초점: OCR은 텍스트 인식에 초점을 맞추는 반면, Layout Analysis는 문서의 전체적인 구조와 레이아웃을 이해하는 데 중점을 둡니다.
- 결과물: OCR의 결과는 텍스트입니다. Layout Analysis의 결과는 문서의 구조적 특성에 대한 정보, 예를 들어 텍스트 블록, 이미지의 위치, 페이지 레이아웃 등입니다.
비슷하지만 서로 다른 이 두 기술은 함께 사용되어 이미지의 정보 추출 프로세스를 고도화 할 수 있습니다. 예를 들어, Layout Analysis를 사용하여 문서의 구조를 파악한 후, 해당 구조에 따라 OCR을 적용하여 텍스트를 효과적으로 추출할 수 있습니다.
Layout Analysis 방식의 이점
- 문맥적 이해: Layout Analysis는 문서의 구조와 레이아웃을 분석하여, 각 줄이나 항목이 문서 내에서 어떤 역할을 하는지 이해할 수 있게 해줍니다. 이는 단순히 텍스트를 인식하는 것 이상의 정보를 제공하여, 데이터의 문맥적 이해를 가능하게 합니다.
- 정확성 향상: 세부산정내역서 내의 데이터를 적절한 문맥에서 해석할 수 있게 되므로, 데이터 추출의 정확성이 향상됩니다. 예를 들어, 세부산정내역 표에서 숫자로 사용하는 형식의 일자, 코드, 또는 금액, 횟수, 일수 등이 다르게 해석될 수 있는 경우, 레이아웃 분석을 통해 각 숫자의 정확한 의미를 파악할 수 있습니다.
Layout Analysis에 의한 문서 구조의 이해와 섹션 식별은 이 텍스트가 어떤 정보인지를 결정하는 데 중요한 역할을 합니다. 예를 들어, Layout Analysis는 진료비 세부산정내역서에서 환자 정보와 진료비 내역 표 섹션을 식별하고, 섹션 내에서도 코드, 금액, 비급여 등 컬럼에 따라 세부 정보를 분류할 수 있습니다.
따라서, Layout Analysis는 직접적으로 정보를 추출하지 않지만, 문서의 구조를 이해하고 텍스트가 위치한 문맥을 파악하여 OCR 처리의 정확도와 효율성을 높이는 역할을 합니다. 이 과정은 텍스트 정보의 자동화된 분류와 추출을 가능하게 하여 전체적인 문서 처리 과정을 최적화합니다.
3. 활용 사례 (업스테이지 Layout Analyzer)
논문의 예시보다는 실제 Layout Analysis 기술이 현업에서 활용되고 있는 사례를 살펴보는 것이 기술을 이해하는 데 더 도움이 될 것이라 생각해, 업스테이지에서 공개한 Layout Analyzer에 대해 리뷰하겠습니다.
https://www.content.upstage.ai/blog/business/introducing-layout-analysis
‘Layout Analyzer’ 를 소개합니다. — Upstage
단순한 글자 인식을 넘어 문서 구조를 자동으로 이해하고 손쉽게 추출하도록 설계된 강력한 API, ‘Upstage Layout Analysis’를 소개합니다.
www.content.upstage.ai

요약
Layout Analyzer의 Element detection 기능은 문서에서 다양한 요소를 인식하고 텍스트를 추출합니다. 이는 요소에 대한 정보를 이해하고 텍스트를 추출하기 때문에 OCR 기술을 사용해 텍스트를 추출하는 것보다 더 정확하고 효율적으로 데이터를 추출할 수 있습니다. 또한, HTML 코드로 변환이 가능해서 글자 크기를 다르게 인식할 경우 일괄적인 수정이 가능하다고 합니다.
세부 설명
Header(문서에서 반복되는 상단 글자), Footer(문서에서 반복되는 하단 글자), Paragraph, Caption(이미지, 테이블 등의 캡션), Table(표 인식), Image(이미지, 그래프) 등을 인식하여 따로 저장하는 것이 가능합니다. 각각의 요소에 대한 이해를 바탕으로 텍스트를 검출할 수 있기 때문에 데이터를 깔끔하게 추출할 수 있는 것이 특징입니다. 특히 표, 차트가 다단에 같이 존재하는 경우 이를 한 줄로 인식하여 제대로 된 데이터를 추출하기가 어려운데, Layout Analyzer를 활용하면 추출이 한층 쉬워진다고 합니다.
또한, 문서 구조를 인식한 결과를 HTML 코드로 다운로드 받을 수 있습니다 어떤 문서라도 Layout Analyzer를 거치면 HTML 코드로 변환이 가능합니다. 요소 단위로 HTML 코드를 반환할 수 있기 때문에 단위별로 수정할 수도 있습니다. 나아가서 글자 크기도 다르게 인식할 수 있기 때문에 해당 크기의 요소에 태그를 달고 일괄적으로 수정할 수도 있습니다.
글자 크기도 font-size 요소로 구분이 가능하기 때문에 문서에서 큰 글자와 작은 글자를 구분해서 DB화 할 수 있을 뿐만 아니라, 글자 크기도 숫자로 저장 가능합니다.
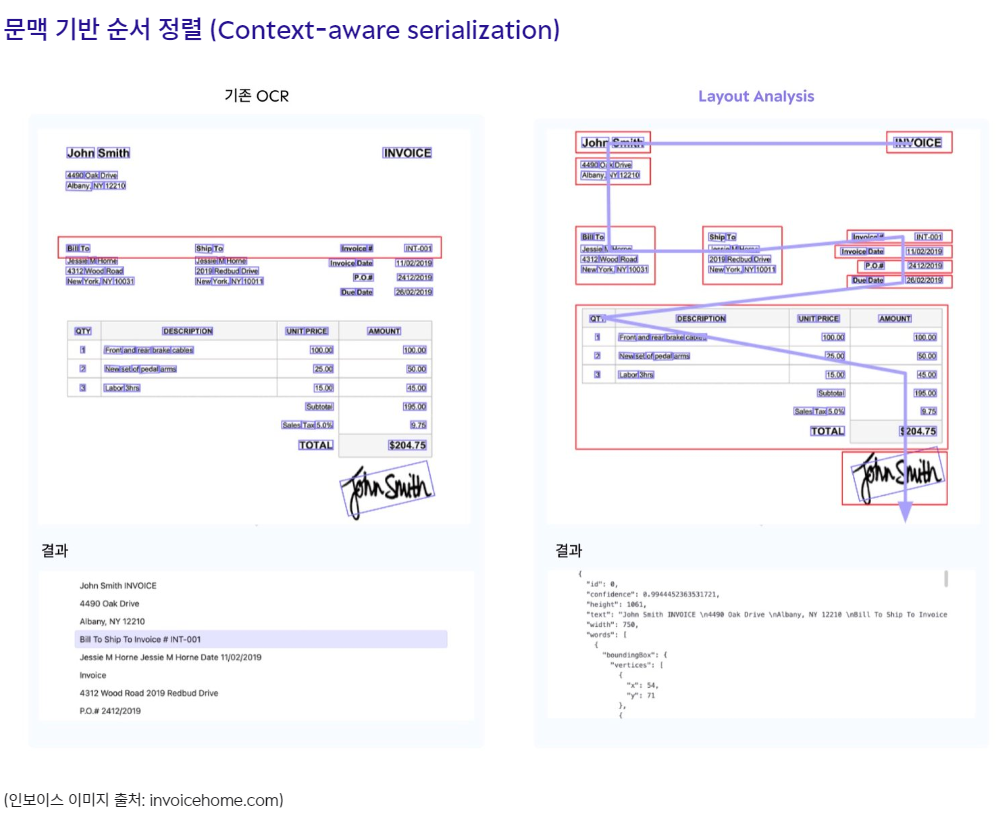
세부 설명
Layout Analyzer는 사람이 문서를 인식하듯이 문맥에 맞게 글자를 읽는 순서대로 데이터를 추출할 수 있습니다. 기존 OCR은 문서의 구조와 관계없이 텍스트만을 인식하여 정보 단위상 한 줄로 읽으면 안되는 글도 한 줄로 읽어내곤 합니다. 문서 구조를 분석하고 정보의 덩어리를 인식하는 Layout Analyzer 기능은 텍스트 추출 후 적용해야했던 복잡한 데이터 전처리 작업들을 생략할 수 있다고 합니다.
++
정보 단위상 한 줄로 읽으면 안되는 글을 한 줄로 읽어낸다면, 한 줄로 읽어야 하는 글은 한줄로 읽도록 할 수 있지 않을까? 라는 생각이 듭니다.
EX) 표의 항목 명칭이 너무 길어서 두줄로 인식해 데이터를 두번 추출하는 경우의 문제를 해결해줄 수 있지 않을까?

세부 설명
Layout Analyzer는 요소 간 관계를 추출하며, 특히 표와 캡션, 그리고 그림과 캡션 사이의 관계를 탐지합니다. 관계를 탐지한다는 것은 표나 그림의 캡션이 상호참조되어, 표를 인식하면 해당 표에 대한 설명이 캡션으로 라벨링 되어 있고, 캡션을 지정하면 그에 대한 표를 바로 렌더링해서 볼 수 있다는 것을 의미합니다. 이러한 장점 덕분에 텍스트만 추출하더라도 전체 문서의 맥락을 이해하기 쉽습니다.
5. 실제로 적용이 가능한가?
Document Layout Analysis
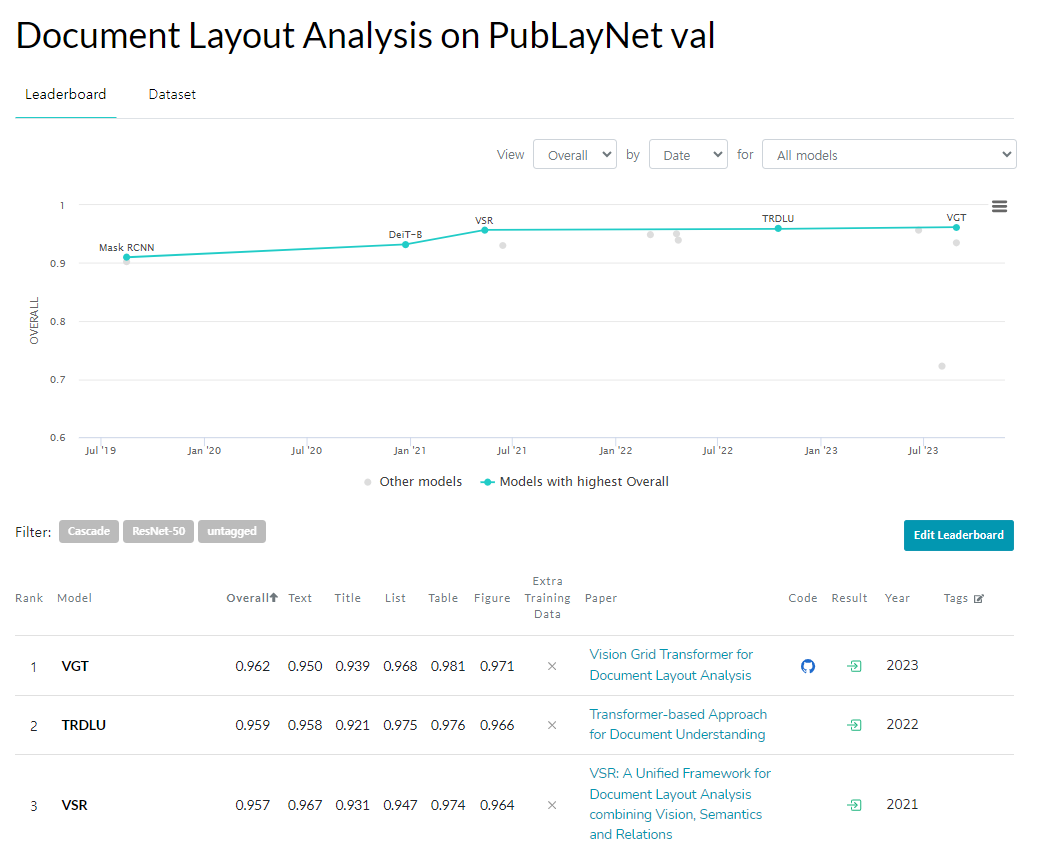
Paper with code에서 SOTA 모델부터 MASK RCNN, Faster RCNN 모두 90%이상의 성능을 보이고 있습니다. 우리가 관심 있는 부분은 세부산정내역서에 큰 비중을 차지하는 Table을 잘 구분하느냐 역시 90% 이상의 성능으로 잘 구분하고 있는 것으로 확인됩니다.
그러나, Table (표) 내의 셀 구조를 인식하고, 필요한 영역만을 추출해줄 수 있을지는 확인해볼 수 없었습니다.
이에 리서치를 진행하던 중 문서 이미지에서 표를 탐지하고 구조를 인식하는 논문을 찾았습니다.
"DeepDeSRT: Deep Learning for Detection and Structure Recognition of Tables in Document Images" (2018)
논문 "DeepDeSRT: Deep Learning for Detection and Structure Recognition of Tables in Document Images"는 문서 이미지에서 표를 탐지하고 그 구조를 인식하기 위한 딥러닝 기반의 기술에 대해 다룬 논문입니다. 이 논문은 크게 두 부분으로 구성되어 있습니다.
- 테이블 탐지: 이 부분에서는 Faster R-CNN을 사용하여 문서 이미지 내에서 테이블의 위치를 탐지합니다. Faster R-CNN은 물체 탐지에 널리 사용되는 프레임워크로, 문서 이미지에서 테이블을 탐지하는 데에도 효과적임을 보여줍니다.
- 테이블 구조 인식: 탐지된 테이블의 구조, 즉 행, 열, 셀의 위치를 인식하기 위해 FCN (Fully Convolutional Network) 기반의 시멘틱 세그멘테이션 모델을 사용합니다. 이 모델은 이미지를 픽셀 수준에서 분류하여 테이블의 구조를 세밀하게 인식할 수 있게 합니다.
논문은 이 두 단계를 통해 문서 이미지에서 테이블을 정확하게 탐지하고 그 구조를 인식할 수 있는 시스템의 구현과 성능 평가 결과를 제시합니다. 테이블 탐지에 있어서는 ICDAR 2013 데이터셋을 기반으로 높은 정확도를 달성했으며, 테이블 구조 인식에서도 우수한 결과를 보였습니다.
이러한 결과는 문서 이미지 내 테이블 탐지와 구조 인식의 가능성을 시사합니다.
마치며...
이를 통해 OCR 모델에 Layout analysis 기술을 접목하면 OCR 인퍼런스 결과의 정확도와 효율성을 개선할 수 있을 것이라 생각했습니다. 다음 글에서는 Layout analysis의 논문들을 하나씩 리뷰하고, 직접 구현하면서 OCR 모델에 접목 시킬 수 있을지 POC를 진행해보겠습니다.