1. 서론
문서 내 표 영역의 경우, 표 내부 항목명과 항목 내용을 인식하는 것은 업무 자동화를 위한 문서 처리 에 있어서 중요한 부분입니다. 하지만 OCR만을 통해서는 표 내부의 문자를 인식하는 것에만 국한되어있고, 해당 내용이 무슨 의미를 가지는지는 인식을하지 못합니다. 따라서 문서 인식을 수행한 후, 사람의 손으로 항목을 분류해야 한다는 불편함이 있으며, 표 영역 내 구분자는 문자 인식의 정확도를 떨어뜨리는 요인이 되기도 합니다.
본 논문에서는 딥러닝 신경망을 통해 표 항목 내의 문자를 인식하고, 이를 통해 문서를 디지털화하는 방법을 제안합니다. 먼저 스캔된 문서 이미지 파일에서 CNN을 통해 표 영역을 검출합니다. 그 후, 표 영역 내 수직선과 수평선의 구분자로 분리된 각 영역을 검출한 후, 각각의 영역에 대해 CNN과 RNN이 결합된 신경망을 통해 문자를 인식합니다.
2. 관련연구
다중 객체를 검출하기 위해서는 영상 내 객체가 있을만한 영역으로 분할한 뒤, 각각의 영역들을 객체 인식을 위한 CNN에 입력하여 각각의 객체를 인식합니다. 다중 객체를 위한 영상 인식 CNN은 1-stage 방법과 2-stage 검출 방법으로 분류됩니다.
2-stage 방법
2-stage 방법은 객체가 있을 확률이 높은 영역을 검출한 후, 검출된 영역에 대해 정확한 영역 검출과 객체를 분류하는 과정을 순차적으로 수행하는 방법입니다.
기존의 R-CNN 방법은 객체가 존재할 가능성이 높은 경계박스를 찾기 위해 selective search 알고리즘을 적용했는데, 이 알고리즘은 인공신경망과 별도로 수행되기 때문에 학습이 되지 않는 문제가 있습니다. 이러한 단점을 개선한 것이 Fast R-CNN 입니다.
Fast R-CNN은 영역 분할을 위해 RPN을 적용하여 영역 분할 과정을 신경망에 통합하여 객체 인식의 전체 과정을 학습 시킬 수 있으며, 한 영상 전체에 대한 특징맵을 구하여 영역 분할 후 전체 특징맵에서 해당 영역에 대한 것만을 사용하기 때문에 속도 역시 개선했습니다.
1-stage 방법
1-stage 방법은 영상을 특정 단위의 사각형으로 분할하여 처리하는 것이 특징입니다. 이를 통해 2-stage 방법에 필요한 영역 제안 과정이 생략되고, 분할된 각 영역에서 객체 영역 검출과 객체 분류가 동시에 이뤄집니다. 이 후 각 영역에서 검출된 결과들을 통합하여 최종적인 객체 인식 결과를 구합니다.
YOLO는 R-CNN 방법들과 달리 1-stage 검출기인데 객체 검출문제를 회귀 문제로 정의합니다. 입력 영상은 특정한 크기의 셀로 분할되는데, 각각의 셀에서 검출할 물체의 신뢰도가 계산 됩니다.
일반적으로 1-stage 방법은 2-stage 방법보다 객체 검출 속도가 빠르지만, 객체 검출 정확도는 떨어집니다.
3. 실험
본 논문에서 문서 내 표 항목의 내용을 인식하기 위한 흐름은 다음과 같습니다.
- CNN를 통해 표 영역을 검출하는 단계
- 검출된 영역에서 구분자를 검출하여 각각의 항목으로 분할하는 단계
- 분할된 항목에서 문자를 인식하는 단계
- 인식된 결과를 규격화된 파일 포맷으로 저장하는 단계로 이루어집니다.
CNN를 통해 표 영역을 검출하는 단계

표 영역 검출 모델
Faster R-CNN(Backbone에 ResNet-101 적용)
Faster R-CNN에서 ResNet-101을 Backbone 신경망으로 사용한다는 것은, Faster R-CNN 모델이 객체 탐지를 수행하기 위해 이미지로부터 특징을 추출할 때, ResNet-101의 구조를 활용한다는 의미.
학습 데이터
표가 포함된 500개의 문서 이미지(이미지 + 경계 박스의 좌표 학습)
학습 Epochs
100회
위의 과정을 통해 학습된 신경망을 통해 검출된 표의 영역은 Fig 3와 같습니다.
검출된 영역에서 구분자를 검출하여 각각의 항목으로 분할하는 단계
표 내부의 각 항목에 구분자가 있을 경우 해당 구분자로 인해 문자 인식 정확도가 저하됩니다. 이를 개선하고 항목을 구분하고자 아래와 같은 알고리즘을 적용했습니다.
적용 알고리즘
- Canny 알고리즘 : 영역 내 외곽선을 검출. (표 내의 구분자를 제거하고, 표 내의 각 항목을 구분)
- Douglas-Peucker 알고리즘 : 외곽선을 이루는 꼭지점 검출. (연결된 하나의 외곽선에서 꼭짓점이 4개일 경우, 해당 외곽선을 표를 이루는 구분자로 검출)
여기서 표 전체의 외곽을 둘러싸는 사각형이 검출되는 경우를 고려하여 검출된 사각형들 간의 포함관계를 조사하여 2개 이상의 사각형을 포함하는 사각형은 제외.
이를 통해 Fig 4. 처럼 표 영역에서 항목 영역을 검출합니다.
분할된 항목에서 문자를 인식하는 단계
본 논문에서는 표 내의 항목을 인식하기 위해 CNN과 RNN을 결합한 신경망을 적용합니다.
- CNN층에서 표 내 각 항목 영역의 이미지를 입력 받아 해당 이미지에 대한 특징 맵을 검출합니다.
- RNN층에서는 CNN층에서 추출된 이미지의 특성을 Bi-LSTM 구조를 활용하여 시계열 데이터의 특징을 추출합니다.
- CTC 층을 통해 정렬된 형태로 인식된 텍스트를 출력합니다.
기존 OCR과의 차이점은 표 내 각 항목 영역의 이미지를 입력 받는다는 것입니다.
인식된 결과를 규격화된 파일 포맷으로 저장하는 단계
문자 인식 결과를 csv나 엑셀 파일 등 규격화된 파일 포맷으로 저장합니다. 이를 통해 표 내부의 항목 별 내용을 디지털화하여 자동으로 문서 처리를 수행합니다.
Fig. 6은 해당 과정을 통해 규격화된 문서로 저장된 결과입니다.

이 논문에서는 각각의 인식 정확도를 판단하여 상위 3개의 인식 결과와 해당 문자가 있는 영역을 같이 제시하여 사용자가 직접 판단하게 함으로써 오인식으로 인한 서류 자동화의 오류를 사전에 차단하고 있습니다.
4. 실험결과
본 논문에서 제안하는 방법의 정확도를 측정하기 위해 한글 문서 10장, 영어 문서 5장을 스캔하여 실험을 수행했습니다.
Fig. 7은 실험에 쓰인 문서 이미지입니다.
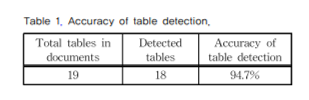
표 검출 방법의 정확도를 측정한 결과는 Table 1과 같습니다. 이 때 총 19개의 표 중에 18개의 표를 검출하여 94.7%의 검출 정확도를 보여 CNN 신경망을 통해서 표가 거의 정확하게 검출이 된 것을 확인할 수 있습니다.
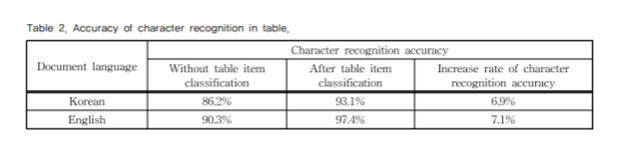
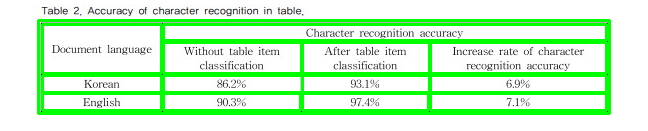
제안된 방법을 통해 표 영역에서 문자 인식의 정확도는 Table 2와 같습니다. 이 때, 표 항목 분류를 수행하지 않고 문자 인식을 했을 때는 표의 항목을 구분하는 세로 줄과 같은 구분자가 별도의 문자로 인식되어 전체적인 문장의 인식률이 저하됐습니다.
반면 표 항목 분류를 수행한 후 문자 인식을 수행한 결과는 문자 인식 정확도가 약 7% 증가했습니다. 이는 표 항목 분류를 통해 의미가 다른 표 항목이 같은 문장으로 인식되지 않고, 별개로 인식이 수행되어 시계열을 처리하는 신경망인 RNN의 성능이 좋아졌기 때문입니다.
5. 직접 구현
코드 구현 깃허브 주소
레이아웃 검출 모델
ResNet-101을 백본으로 사용한 Faster R-CNN 모델에 TableBANK 데이터셋으로 사전학습된 모델을 사용하여 문서에서 Table(표)에 해당하는 영역을 검출했습니다.
세부 영역 검출 알고리즘
- Canny 알고리즘 : 영역 내 외곽선을 검출. (표 내의 구분자를 제거하고, 표 내의 각 항목을 구분)
- Douglas-Peucker 알고리즘 : 외곽선을 이루는 꼭지점 검출. (연결된 하나의 외곽선에서 꼭짓점이 4개일 경우, 해당 외곽선을 표를 이루는 구분자로 검출)
두 가지 알고리즘을 파이썬 opencv 라이브러리로 구현해봤습니다.
아래는 구글에서 표 이미지를 검색해 문서 내에서 테이블을 검출해봤습니다.

문서 내의 테이블을 잘 잡아내는 것을 볼 수 있습니다.
이를 Canny 알고리즘과 Douglas-Peucker 알고리즘을 사용해서 세부 영역으로 나눠보겠습니다.

그림을 보면 세부 영역을 확실하게 나누고 있지만, 텍스트도 영역으로 인식하는 문제가 있습니다. 이는 인지한 사각형의 넓이와 높이를 조절해서 처리할 수 있습니다.
이번에는 본 논문의 페이지 내에서 다중 테이블을 검출해보겠습니다.


다중 테이블 역시 잘 잡아내고 세부 영역을 확실하게 나누고 있습니다.
6. 한계점
그러나 실제로 서비스에서 문서 인식 서비스를 진행할 때, 항상 깔끔한 이미지를 인식하지 못합니다.
예를 들어 보험금을 청구할 때 진료비 영수증을 보면 표가 굉장히 많이 그려져있는데, 환자들은 핸드폰으로 이를 촬영해서 전송합니다. 이 때, 잘 찍으시는 분들도 존재하지만 이미지가 기울어지거나 영수증이 구겨져 있는 등 이미지에 노이즈가 있는 경우 테이블이 이를 제대로 인식하지 못합니다.
개선방안
진료비 영수증은 스캔본, 구겨진 이미지, 그림자 등 다양한 형태가 존재하는데 사전 학습 모델은 이러한 이미지를 학습하지 못했습니다.
→ 다양한 형태에 대해서도 레이아웃을 검출할 수 있는 레이아웃 분류 모델을 개발합니다.
현재는 세부 영역 검출 시 꼭짓점을 이어서 사각형을 만들고 있는데, 선이 없는 경우 세부 영역을 검출할 수 없습니다.
→ 표의 헤더에는 선이 존재하므로 헤더를 기준으로 열 단위로 세부 영역을 나누는 등 새로운 방법을 탐색합니다.
→ 테이블의 셀과 같은 세부 영역을 검출할 수 있는 레이아웃 분류 모델을 개발합니다.
7. 결론
본 논문에서는 문서 처리를 자동화하기 위해 표가 포함된 문서에 대해 딥러닝 신경망을 통해 항목 별 내용을 분류하고 항목 내 문자를 인식하는 방법을 제안했습니다.
Fast R-CNN 모델에 TableBANK 데이터셋을 학습한 모델을 사용해 여러 문서에서 테이블을 검출해봤습니다. 해당 문서의 이미지를 학습하지 않았지만 문서 내 테이블의 위치를 잘 파악하고 있습니다.
그러나, 기울어진 이미지, 구겨진 이미지 등 에서는 정확한 위치를 잡아내지 못하는 것을 확인했습니다. 기울어진 이미지에 대해 바운딩 박스를 라벨링하고 학습을 진행한다면 기울어진 표를 파악할 수 있을 것이라 생각하나, 세부 영역 셀도 나눠야하는 등 여러 한계점이 존재하여 자체 개발을 진행할 시 많은 비용이 소모됩니다.
이러한 레이아웃을 검출하고 분류할 수 있다면 OCR의 정확도와 효율성을 향상시킬 수 있습니다.
- 텍스트 영역 식별: 문서 내의 레이아웃을 분석함으로써 OCR 모델은 텍스트가 있는 영역과 그렇지 않은 영역을 구분할 수 있습니다. 이는 모델이 텍스트 추출 과정에서 중점을 둬야 할 부분을 결정하는 데 도움을 줍니다.
- 정보 구조 이해: 레이아웃 분석을 통해 헤더, 푸터, 본문, 캡션 등 문서의 다양한 섹션을 식별할 수 있습니다. 이러한 구조적 이해는 정보를 보다 정확하게 추출하고 분류하는 데 기여합니다.
- 효율성 향상: 불필요한 영역을 무시하고 텍스트 추출에 집중함으로써 OCR 프로세스의 속도와 효율성을 높일 수 있습니다.
- 오류 감소: 레이아웃 정보를 활용함으로써 OCR 모델은 텍스트를 더 정확하게 인식할 수 있습니다.
마치며...
논문의 이미지, 비즈니스 문서들의 경우 깔끔한 이미지여서 해당 기술을 적용하면 OCR 성능을 향상 시킬 수 있을 것이라 생각합니다.
그러나, B2C 서비스에서 OCR 모델을 사용할 경우 깔끔하지 못한 이미지들이 들어올 가능성이 높으며 모델이 이를 인식하지 못할 수 있습니다.
이러한 깔끔하지 못한 문서들에서도 세부 영역을 검출할 수 있는 모델을 개발할 필요가 있습니다.