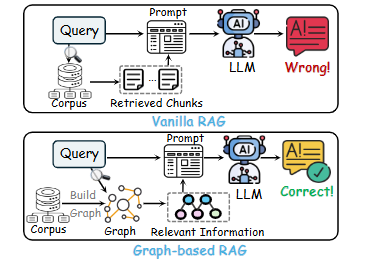
안녕하세요! 이전에 GraphRAG와 LightRAG에 대해 함께 살펴보았는데요, 오늘은 그 흐름을 이어 GraphRAG 분야의 또 다른 흥미로운 아이디어를 소개해 드리려고 합니다. 바로 2025년 4월 15일에 올라온 'NodeRAG: Structuring Graph-based RAG with Heterogeneous Nodes' 라는 논문인데요, 다양한 정보 유형을 각기 다른 종류의 노드로 표현하는 '이종 그래프' 구조를 체계적으로 설계하고 활용하자는 핵심 아이디어를 제시하고 있습니다. 이 아이디어를 통해 기존 모델들(GraphRAG, LightRAG)과 어떻게 다르고 어떤 점을 개선했는지 논문 리뷰를 통해 전달드리고자 합니다. 0. AbstractRAG 기술은 LLM(대규모 언어 모델)이 외부 또는..