KBLaM
https://arxiv.org/abs/2410.10450
KBLaM: Knowledge Base augmented Language Model
In this paper, we propose Knowledge Base augmented Language Model (KBLaM), a new method for augmenting Large Language Models (LLMs) with external knowledge. KBLaM works with a knowledge base (KB) constructed from a corpus of documents, transforming each pi
arxiv.org
2025년 3월18일 마이크로소프트에서, LLM에 지식을 직접 주입하는 새로운 방식(KBLaM)을 공개했습니다.
그러나, 아직 프로덕션 환경에서 완전한 시스템으로 사용하도록 의도한 것은 아니고 연구 프로젝트를 공유한 것이라 밝혔습니다.
제가 이 논문을 관심있게 본 이유는 여러 RAG 프로젝트를 진행하면서 느낀 한계점을 지적하였고, 이를 극복할 수 있는 방식인 KBLaM이라는 새로운 방법론을 소개했기 때문입니다.
KBLaM 논문에서 지적한 기존 RAG(Retrieval-Augmented Generation)의 한계점은 다음과 같습니다:
- 외부 검색 모듈 의존
RAG는 문서에서 관련 정보를 검색하기 위해 외부 검색 모듈을 사용합니다. 이로 인해 시스템이 복잡해지고, 검색 모듈의 정확도에 따라 전체 성능이 크게 영향을 받을 수 있습니다. - 비효율적인 지식 통합
RAG는 검색된 문서를 LLM의 컨텍스트 창에 추가하여 처리합니다. 하지만 컨텍스트 창의 크기가 제한적이어서 대규모 지식 기반을 효율적으로 활용하는 데 어려움이 있습니다. - 동적 업데이트의 어려움
지식 기반이 업데이트될 경우, RAG는 검색 인덱스를 새로 구축해야 할 수 있습니다. 이 과정은 많은 자원을 소모하며 비효율적입니다. - 해석 가능성 부족
RAG는 모델이 어떤 정보를 사용했는지 명확히 알기 어려워 해석 가능성이 떨어집니다. 이는 모델이 잘못된 정보를 생성하는 환각(hallucination) 문제를 일으킬 수 있습니다.
실제 RAG 프로젝트를 진행하다보면 응답속도와 정확도가 가장 큰 문제인데요.
현업 요구사항이 주로 응답속도와 정확도이기 때문입니다. 그러나, 두 요구 사항을 충족시키는 것에 어려움이 있습니다.
정확도를 위해선 다단계 의사결정 프로세스나 복잡한 워크플로우를 포함해야 하지만 응답속도가 빠르려면 최소화해야 하는 trade-off 관계이기 때문입니다.
예를 들어, 금융 도메인에선 고객에게 잘못된 정보(할루시네이션)을 제공하는 것이 치명적일 수 있고, 평균 연령대가 높은 편이라 응답이 느리면 불편함을 호소하는 고객이 많습니다.
할루시네이션 체크를 위해 여러 검증 로직을 구현하고, 정보 중요도에 따라 검색 방법 역시 다르게 하고 있습니다.
이를 통해 할루시네이션을 최소화 하고 있지만, 모든 케이스를 커버하기는 어렵습니다.
또한, 조건부 라우팅으로 의도에 맞게 워크플로우가 수행되지만 프로세스가 추가 되고 컨텍스트가 길어질 경우 응답속도에도 영향을 미칩니다.
그럼 이제 위와 같은 RAG의 한계점을 KBLaM은 어떻게 풀어나갔는지 리뷰해보도록 하겠습니다.
0. 초록
1. 소개
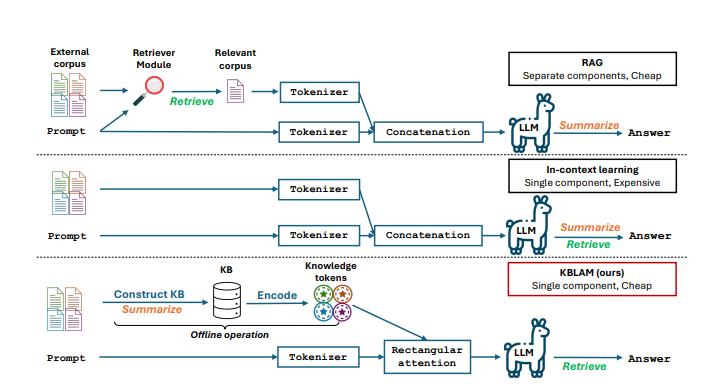
소개 섹션에서는 LLM에 외부 지식이 필요한 이유를 강조합니다. 모델의 내부 표현에 없는 세부 정보를 처리하기 위해 외부 지식이 필수적이며, 기존 방법의 한계를 지적합니다. supervised 미세 조정은 비효율적이며, catastrophic forgetting을 초래할 수 있고, RAG(Retrieval-Augmented Generation)는 외부 검색 모듈이 필요하기 때문이라고 합니다.
문제점:
- LLM은 방대한 텍스트 데이터로 사전 훈련되지만, 특정 도메인 지식이나 최신 정보가 부족하고 때로는 부정확하거나 환각(hallucination)적인 정보를 생성하는 경향이 있습니다.
기존 해결책 및 한계:
- 파인튜닝(Fine-tuning): 새로운 지식을 통합하기 위해 모델 전체 또는 일부를 재훈련해야 하므로 비용이 많이 들고 지속적인 업데이트가 어렵습니다.
- 검색 증강 생성(RAG): 외부 지식 소스에서 관련 정보를 검색하여 LLM의 입력으로 제공합니다. 하지만 검색 시스템의 성능에 의존하며, 검색 결과가 부정확하거나 관련 없으면 LLM의 성능 저하로 이어질 수 있습니다. 또한 별도의 검색 인덱싱 및 검색 단계가 필요합니다.
- 인컨텍스트 학습 : LLM의 입력 프롬프트에 직접 지식 예시나 정보를 포함시키는 방식입니다. 효과적일 수 있으나 LLM의 제한된 컨텍스트 길이(context window) 때문에 포함할 수 있는 지식의 양이 제한적이며, 입력 길이가 길어짐에 따라 주의 메커니즘의 계산 복잡도가 제곱으로 증가(quadratic complexity)하는 문제가 있습니다.
KBLaM은 이러한 문제를 해결하기 위해 지식 기반(KB)을 직접 LLM에 통합하는 방법을 제안합니다. 이 접근법은 KBLaM은 별도의 검색 모듈 없이도 KB의 지식을 활용할 수 있으며, KB 크기에 따라 선형적으로 확장 가능하고, 지식 업데이트 시 모델 재학습 없이도 동적으로 지식을 변경할 수 있다는 장점을 가집니다. 또한, 모델이 어떤 지식 토큰에 집중하는지 해석할 수 있는 능력도 제공합니다.
2. 관련연구
KBLAM은 기존의 RAG와 비슷하게 외부 지식을 LLM에 통합하지만, retriever 없이 attention 메커니즘만으로 이를 수행한다는 점에서 중요한 차별점을 가집니다. 또한 Structured Attention의 효율적인 연산 구조와 KV Cache의 빠른 토큰 생성 구조를 모두 참고하여, 지식 통합의 계산 효율성과 해석 가능성을 동시에 확보하고자 합니다.
이러한 점에서 KBLAM은 복잡한 검색 단계를 제거하면서도 지식 기반 확장을 효과적으로 달성하는 새로운 방향성을 제시하고 있습니다.
3. 배경
배경 섹션은 KB의 구조와 트랜스포머의 self attention layer를 설명합니다. KB는 (<이름>, <속성>, <값>) 트리플로 구성되며, 이는 모델이 이해하고 통합할 수 있는 형식입니다. self attention layer는 LLM의 핵심 구성 요소로, KBLaM이 이 메커니즘을 어떻게 수정하여 지식 토큰을 통합하는지 이해하는 데 필요한 기초를 보여주고 있는 섹션입니다.
지식 베이스 구조 (Knowledge Base, KB) :
지식베이스는 다음과 같은 삼중(triple) 구조의 정보 집합으로 표현됩니다. 각 트리플 별 예시도 함께 합성 KB 데이터 예시도 논문에 함께 보실 수 있습니다.
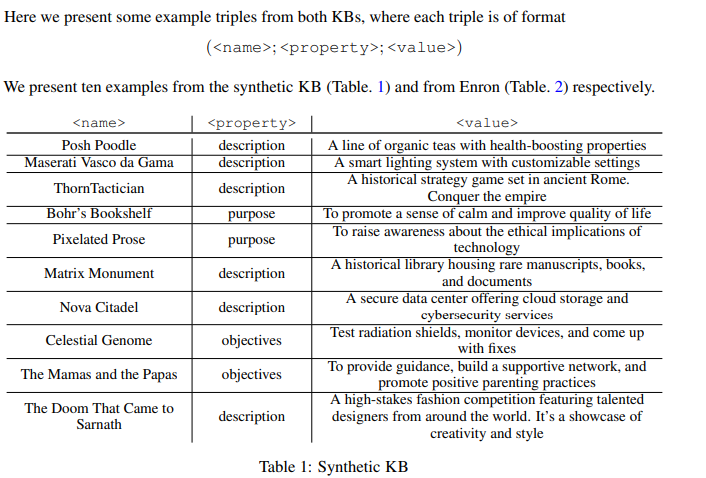
위와 같은 각 삼중 구조는 **지식 트리플(knowledge triple)**이라 불리며, 이들이 모여 전체 KB를 구성합니다.
구조화된 KB는 비구조적인 텍스트로부터 자동 추출된다고 하는데요, 다양한 문서로부터 핵심 정보를 요약하고 정리하는 방식라고 합니다.
본 논문에서는 두 가지 KB를 사용하고 있습니다.
- 합성(Synthetic) KB: GPT를 활용해 생성
- 실제 KB: Enron 이메일 데이터셋을 기반으로 생성 (Klimt & Yang, 2004)
이러한 KB는 구조화되어 있기 때문에, 비구조 텍스트보다 훨씬 효율적으로 LLM에 정보를 통합할 수 있다는 가정으로 다음 섹션이 쭉 이어집니다.
Transformer의 Self-Attention 구조 :
KBLAM이 작동하는 기반이 되는 구조는 저희가 잘 알고 있는 트랜스포머의 self-attention 입니다.
트랜스포머의 구조는 다른 자료가 많기도하고, LLM을 공부하신다면 보통 이해하고 있으실테니 스킵하도록 하겠습니다.
단, 이 트랜스포머의 구조는 시퀀스 길이에 따라 계산/메모리 비용이 제곱으로 증가하여, 긴 입력 처리에 비효율적이라는 단점만 알고 넘어가시면 좋을 듯 합니다.
4. AUGMENTING LLM WITH THE KB
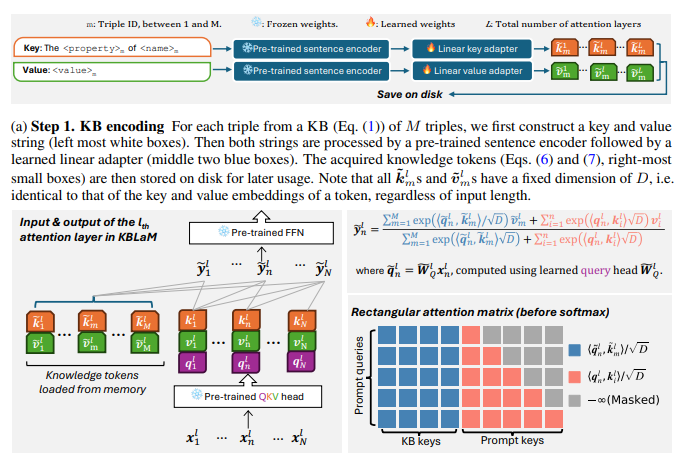
KBLAM(Knowledge Base augmented Language Model)은 대형 언어 모델(LLM)에 지식 기반(KB)을 효과적으로 추가하는 방법을 제안합니다. 이 방법은 두 가지 핵심 단계로 구성됩니다.
1. 지식 토큰(Knowledge Tokens) 생성 : 사전 학습된 문장 인코더와 선형 어댑터를 통해 KB의 각 트리플을 문자열 형태에서 지식 토큰이라고 하는 연속 키-값 벡터 쌍으로 변환하고,
- KB에 있는 각 triple (<name>, <property>, <value>)을 두 개의 문장으로 나눕니다:
- Key용 문장: "The <property> of <name>"
- Value용 문장: "<value>"
- 이 문장들은 고정된 사전학습 sentence encoder (예: BERT)로 임베딩되어 각각 P차원의 base key, base value 벡터로 변환됩니다.
- 삼중항 변환: 각 삼중항 <name>, <property>, <value>에 대해, 사전 훈련된 문장 인코더 f(·)를 사용하여 키와 값 임베딩을 생성합니다:
- 키 임베딩: km = f(The <property> of <name>)
- 값 임베딩: vm = f(<value>)
선형 어댑터 적용: 이후, 학습 가능한 **선형 어댑터(Linear Adapter)**를 통과하여 L개의 어텐션 레이어 각각에 대응하는 (key, value) 쌍으로 확장됩니다. 각 임베딩은 선형 어댑터 W̃K와 W̃V를 통해 LLM의 각 어텐션 층에 맞는 키와 값 임베딩으로 변환됩니다.
- k̃m ∈ ℝ^{L×D}, ṽm ∈ ℝ^{L×D}. 여기서 D는 LLM의 임베딩 차원
- k̃m = W̃K * km
- ṽm = W̃V * vm
- 이렇게 생성된 (k̃m, ṽm) 쌍을 지식 토큰이라 하며, 이는 LLM의 kn, vn과 동일한 크기를 가지며, 동일한 형식(D차원)이므로 self-attention 계산에 직접 통합할 수 있습니다.
2. 직사각형 어텐션(Rectangular Attention) 구조를 통한 통합: 모든 지식 토큰을 직사각형 주의 구조를 통해 LLM의 각 attention layer에 주입합니다.
- 기존의 LLM은 입력 시퀀스 길이 N에 대해 (N×N) 크기의 self-attention을 수행합니다.
- 하지만 KBLAM에서는, 지식 토큰의 개수 M을 추가하여, (N+M) × N 크기의 비대칭 어텐션 행렬을 사용합니다. (이래서 어텐션 행렬이 직사각형 모양이 되기 때문에 직사각형 어텐션이라고 한다네요.ㅋㅋ) 이로 인해, 계산 복잡도가 O((M+N)N) KB 트리플 수(M)에 선형 증가하게 됩니다.
- 지식 토큰이 입력 토큰 길이 N보다 훨씬 많은 경우(M >> N)에도 계산량은 선형 증가하여 대규모 KB 확장이 가능합니다.
- 지식 토큰은 독립적으로 인코딩 되므로 읽히기만 하는 정보로 사용되고, 일부 triple만 바꿔도 전체 재계산 없이 부분 업데이트가 가능하기 때문에 캐시된 콘텐츠가 어떤 식으로든 수정될 경우 다시 계산해야 하는 LLM의 표준 KV 캐시 메커니즘과 KBLAM의 큰 차이점 중 하나이며, 모든 정보를 프롬프트에 넣어 O((M+N)^2)이 되는 인컨텍스트 학습 방식 대비 매우 효율적입니다.
- 직사각형 주의의 출력 시퀀스 길이는 지식 토큰의 수에 따라 달라지지 않으므로 FFN의 오버헤드는 M에 관계없이 변하지 않습니다. 즉, FFN(input/output)에 주는 부담이 없습니다. -> 모델 구조 유지.
해당 섹션이 조금 길었는데 요약하자면,
KBLAM은 Knowledge Base의 triple 정보를 encoder + linear adapter로 처리해, LLM의 각 어텐션 레이어에 key/value 형태의 지식 토큰으로 삽입합니다. 이 지식 토큰은 self-attention 구조를 유지(확장)하면서도, 오직 prompt로부터의 참조만 허용하는 직사각형 어텐션 구조를 통해 삽입되며, 기존 방식들보다 효율적이며 확장성 높은 방식으로 LLM에 외부 지식을 결합할 수 있도록 설계되었다~입니다.
이해가 안되시는 분들을 위해 한번 더 정리하자면,
| In-context Learning | O((N+M)²) | 모든 토큰끼리 연결 |
| KBLAM (Rectangular Attention) | O(N²+NM)=O((N+M)N) | 입력 토큰만 지식 토큰을 attend |
이 방식은 지식 토큰이 많아져도 비용이 선형적으로 증가하므로 대규모 KB 통합에 훨씬 확장성 있고 효율적이라는 겁니다. 지식 토큰이 프롬프트 토큰만 참고하기 때문에 전체 재계산을 할 필요도 없어 확장성 역시 좋은 것이고요!
아 그리고 KB 길이 일반화를 위한 어텐션 스코어 스케일링도 존재하는데, 이는 M이 커질 경우 지식 토큰의 기여도가 과도해질 수 있으므로, 어텐션 스코어에 상수 C를 도입하여 이를 조정할 수 있는 하이퍼 파라미터입니다. 참고만 하시면 될듯 합니다.
5. KB INSTRUCTION TUNING
KBLAM은 LLM에 KB를 효과적으로 통합하기 위해, Instruction Tuning이라는 방식으로 일부 파라미터를 학습합니다. 이 섹션에서는 학습 대상 파라미터, 튜닝 방식, synthetic KB 생성법, 다양한 질문 유형 등 전체 학습 설계를 설명합니다.
5-1. Instruction Tuning 방식 :
Instruction Tuning은 프롬프트(질문)와 응답(정답) 쌍을 만들어서, 주어진 KB에 대해 KBLAM이 적절한 응답을 생성하도록 학습하는 방식입니다.
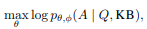
- Q: 질문 (prompt)
- A: 정답 (답변)
- KB: 해당하는 지식베이스
- ϕ: 사전학습된 LLM의 파라미터 (고정. 동결된 파라미터)
- θ: 학습할 어댑터 및 query head
KBLAM은 사전학습된 LLM의 내부 구조는 그대로 두고, 다음과 같은 외부 모듈( θ )만 학습합니다:

- W̃_K, W̃_V: 지식 토큰의 key/value를 LLM의 key/value 공간으로 매핑하는 선형 어댑터
- {W̃_Q^l}: 각 어텐션 레이어의 Query 변환에 쓰이는 학습 가능한 Query 헤드
사전학습된 LLM의 파라미터 ϕ (QKV, FFN 등)는 동결되어 있으며, 직접 업데이트되지 않습니다.
이 방식의 장점은 다음과 같습니다.
- 기존 LLM의 추론 능력 보존
- 선형 어댑터만 학습하여 LLM 미세 조정에서 알려진 문제인 학습 데이터 암기 위험을 최소화할 수 있습니다.
해당 논문에서는 학습 데이터 암기 위험을 더 완화하기 위해 GPT에서 생성한 합성 KB를 사용해 인스트럭션 튜닝을 진행했습니다. 왜 합성 KB가 암기 위험을 완화할 수 있는지 5-2에서 확인하실 수 있습니다.
5-2. Synthetic KB 생성
Instruction tuning에 사용되는 KB는 GPT로 자동 생성된 합성 지식베이스(synthetic KB) 입니다. 이 설계는 두 가지 목적이 있습니다.
- 실제 정보 대신 임의의 구조적 데이터로 구성됨 → 훈련 정보 암기 방지
- 다양한 패턴을 학습할 수 있도록 의미적 다양성 확보
생성 절차:
1. 개체 이름(<name>) 생성
- 기반 정보:
- 30개의 개체 유형 (예: 식당 이름, 소프트웨어 도구 등)
- 30개의 아이디어 유형 (예: 자연 현상, 유명 랜드마크 등)
- 조합 방식:
- 개체 유형(30개)과 아이디어 유형(30개)의 조합(총 900개)을 기반으로 GPT를 사용해 각 조합마다 50개의 <name>을 생성하고, 최종적으로 약 45,000개의 <name>이 포함된 KB를 구축합니다.
(사실 논문에서는 50개의 <name>을 생성하고, 최종적으로 45000개의 이름이 생성됐다로 나와있는데, 제가 중간 과정을 해석해보면 위와 같을 것 같아서 작성했습니다.)
- 개체 유형(30개)과 아이디어 유형(30개)의 조합(총 900개)을 기반으로 GPT를 사용해 각 조합마다 50개의 <name>을 생성하고, 최종적으로 약 45,000개의 <name>이 포함된 KB를 구축합니다.
2. 속성-값(property, value) 생성
- 각 <name>에 대해, GPT에게 다음 3개의 속성에 대한 <value>를 생성하도록 요청:
- "설명" (description)
- "목표" (objectives)
- "목적" (purpose)
- 모든 속성의 값은 **같은 대화 맥락(context)**에서 생성되며, 중요한 제약 조건은 다음과 같습니다:
- GPT가 생성한 <value>가 <name>과 상관없는(random, decorrelated) 값이 되도록 지시
- 이는 모델이 name으로부터 답을 추측하지 못하게 하기 위함이며, 정보를 반드시 KB에서 얻도록 유도
3. 최종 KB 구성
- 결과적으로 생성되는 데이터:
- 약 45,000개의 <name> (30*30*50)
- 총 약 135,000개의 삼중항(triple) → (<name>, <property>, <value>)

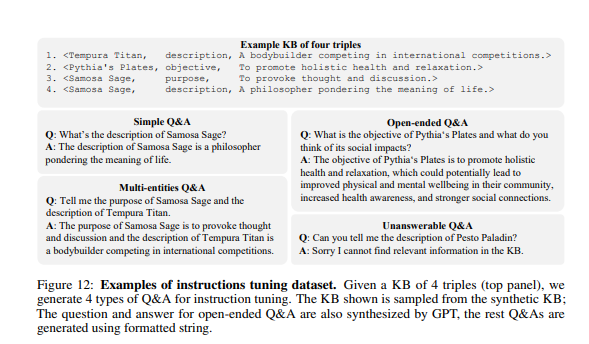
5-3. Instruction 유형 (질문 설계 방식)
Instruction Tuning에서 생성되는 질문은 다음 네 가지 유형으로 구성됩니다:
| (1) 단일 엔티티 Q&A | 한 <name>과 <property>에 대한 질문 → <value>로 응답 |
| (2) 다중 엔티티 Q&A | 여러 <name>과 <property>에 대해 묻고 각각의 <value>를 포함한 응답 생성 |
| (3) 주관식 Q&A | 위와 유사하지만, <value> 기반의 주관식 추론이 요구되는 추가 질문 구성 요소를 포함. (GPT가 참조 응답 생성) |
| (4) 무응답 Q&A | KB에 존재하지 않는 질문을 던져, 모델이 “정보 없음”이라고 응답하도록 훈련 |
이러한 질문들은 질문들은 모두 문장 템플릿 기반으로 자동 생성되는데, 다양한 문장 스타일을 사용하여 LLM의 질문 해석 능력을 강화하기 위함입니다. 템플릿은 아래에서 확인하실 수 있습니다.
6. 실험
모델 구성
- LLM 백본: Llama3 8B (Instruction-tuned 버전)
- 문장 인코더: OpenAI의 text-embedding-ada-002 (임베딩 차원 P=1536)
- 학습 대상 파라미터: 선형 어댑터(W̃_K, W̃_V) 및 어텐션 레이어별 Query 헤드(W̃_Q^l)
- FFN 및 QKV 등 LLM 내부 파라미터는 동결
최적화 및 하드웨어
- 옵티마이저: AdamW
- 러닝레이트: 5e-4 (step), 5e-6 (cosine decay)
- 하드웨어: 단일 80GB A100 GPU (bfloat16 사용)
학습 데이터 구성
- 합성 KB의 상위 120K 트리플로부터 샘플 구성
- 하나의 학습 샘플 = (KB, 질문, 답변)
- KB는 10~100개의 트리플로 구성된 부분집합
- 각 배치(400개 Q&A)는 다음으로 구성됨:
- 단순 질문, 다중 엔티티 질문, 개방형 질문: 각각 6개 마이크로 배치
- 무응답 질문: 2개 마이크로 배치
효율성을 위해 모든 지식 토큰 임베딩은 사전에 오프라인으로 계산해둠
평가 세트
- 합성 데이터: 학습에 사용되지 않은 15,000개의 트리플
- Enron KB: Enron 이메일 데이터를 기반으로 구축된 실제 KB
Baseline
| In-context Learning | KB 모든 트리플을 문자열로 만든 후, 프롬프트에 앞에 삽입. | O((N+M)²) 트리플 수에 따라 4제곱 증가 |
| Zero-shot | 추가 정보 없이 LLM만 사용 | 메모리 적음. |
모든 평가에서 각 실행에 100개의 테스트 샘플이 포함된 5개의 무작위 시드로 실험을 반복합니다. 즉, 다양한 크기의 100KB를 무작위로 생성하고 모델에 해당 KB에 대한 질문으로 쿼리합니다. 아래의 실험 결과는 500개의 모든 질문에 대한 평균값 입니다.
실험 결과

KBLAM은 해석 가능한 리트리버
KBLAM의 가장 흥미로운 점 중 하나는 질문과 관련된 정보를 KB에서 찾아내는 능력을 별도로 가르치지 않았는데도 Instruction Tuning 과정에서 스스로 학습한다는 것입니다. 질문의 핵심 단어(예: <name> 토큰)가 KB 내 관련 정보(지식 토큰)에 높은 '주의(Attention)'를 보내는 패턴을 위 Figure 4에서 확인하실 수 있습니다. 마치 내부에 검색 엔진이 생긴 느낌이네요.
실제로 Top-1/Top-5 정확도를 측정해보니, 합성 데이터는 물론 처음 보는 Enron 데이터에서도 상당히 높은 정확도로 관련 정보를 찾아냈습니다.
- 주어진 질문의 <name> 토큰이 정확하게 해당 지식 토큰에 강한 attention을 보임
- 주의 점수 행렬을 시각화(Fig. 4)하면, KBLAM이 마치 암묵적 리트리버처럼 작동
- 이를 정량화하여 Top-1 / Top-5 정확도로 측정 → 대부분의 경우에서 정답 트리플을 정확히 찾음
- 합성 KB, OOD(Enron) 데이터 모두에서 높은 성능
QA 성능: 높은 정확도 + 뛰어난 확장성
KBLAM은 질문에 답변하는 능력도 뛰어났습니다. 단순 질문부터 여러 정보를 조합해야 하는 질문, 심지어 정답 기반의 추론이 필요한 주관식 질문까지 잘 처리했죠. 평가 결과, 학습 데이터(합성 KB)에서는 기존의 강력한 방법인 In-context learning과 맞먹는 성능을 보였습니다. 놀라운 점은 메모리 사용량은 훨씬 적어서 In-context learning이 수백 개 정보 처리도 버거워하는 반면, KBLAM은 1만 개 이상의 정보(triple)를 다루면서도 성능 저하가 거의 없었다는 것입니다. 처음 보는 실제 데이터(Enron)에서는 비록 성능 저하는 있었지만, 아무 정보 없이 답변하는 것(zero-shot)보다는 훨씬 나은 결과를 보여주며 KB 정보를 효과적으로 활용함을 증명했습니다.
- 질문 유형: 단순, 다중 엔티티, 주관식
- 평가 방법:
- 단순/다중: BERTScore로 자동 정답 비교
- 개방형: GPT-4 평가자를 통한 0~5 점수 부여
- 결과:
- KBLAM은 합성 KB에서 in-context와 유사한 성능
- **Enron(OOD)**에서도 zero-shot보다 확실히 우수
- 10K 트리플까지 확장 가능하며 성능 유지 (in-context는 메모리 때문에 200 트리플 제한)
무응답 탐지: 할 수 없는 질문에 답을 거부할 수 있는가?
AI가 모르는 질문에 대해 솔직하게 '모른다'고 답하는 능력이 정말 중요한 것 같습니다. KBLAM이 이걸 얼마나 잘하는지 KB에 답이 없는 질문(20%)과 있는 질문(80%)을 섞어서 물어봤습니다.
결과적으로, KB에 정보가 많아질수록 KBLAM과 In-context learning 모두 답변 가능한 질문인데도 '정보를 찾을 수 없다'고 잘못 거부하는 경우(over-refusal)가 늘어나는 경향을 보였습니다 (Precision 감소). 하지만 중요한 것은, 실제로 답이 없는 질문에 대해 잘못된 정보를 지어내는 환각(Hallucination)은 두 방법 모두 늘어나지 않았습니다 (Recall 유지).
특히 KBLAM은 In-context learning보다 불필요하게 답변을 거부하는 경향이 훨씬 덜해서, 더 안정적으로 '모른다'고 말해야 할 때와 답해야 할 때를 구분했습니다. 덕분에 '죄송합니다. 관련 정보를 찾을 수 없습니다.' 와 같이 적절한 거절 응답 생성이 가능하다고 합니다.
- 실험 설정:
- 전체 질문 중 80%는 정답이 있는 질문
- 20%는 무응답 질문 (정답 없음 → "정보 없음"이라고 말해야 함)
- 평가 방식:
- 무응답 질문을 positive class로 보고 binary classification처럼 평가
- 측정 지표: 정확도(Accuracy) + 재현율(Recall)
- 실제 실험 결과 요약:
- Recall은 두 모델(KBLAM, in-context) 모두 안정적으로 유지됨
→ 즉, 답할 수 없는 질문을 잘 거부하고 있음 - Precision은 트리플 수가 많아질수록 점차 감소함
→ 즉, 답할 수 있는 질문인데도 "정보 없음"이라고 잘못 거부(over-refusal) 하는 경우가 늘어남 - 그러나 KBLAM의 Precision 감소 폭이 더 작음
→ in-context 학습보다 더 안정적으로 판단하고 있다는 뜻
- Recall은 두 모델(KBLAM, in-context) 모두 안정적으로 유지됨
추가 탐구 연구
덧붙여, KBLAM을 설계할 때 내린 여러 결정들의 효과를 확인하는 실험도 진행되었습니다.
- OpenAI의 인코더 대신 다른 오픈소스 문장 인코더를 사용해도 KBLAM이 작동하며, 인코더 성능에 따라 결과는 달라질 수 있음 (Fig. 7).
- KB 정보를 모든 레이어에 주입하지 않고 더 드문 빈도로 주입해도 작동하며, 효율성은 높아지지만 성능은 약간 저하될 수 있음 (Fig. 8).
- 모델의 초기 레이어에 주입된 지식 토큰이 후반 레이어가 질문을 더 잘 따르도록 돕는 '소프트 프롬프트' 역할을 할 수 있음 (Fig. 9).
7. 결론
본 논문에서는 KBLAM (Knowledge Base-augmented Language Model)을 제안했습니다. 이는 사전학습된 LLM(pre-trained LLM)에 외부 지식베이스(KB)를 효율적으로 통합하는 새로운 방법입니다.
KBLAM은
1. 외부 지식을 dense continuous vectors로 변환하여 표현하고,
2. KB는 <name>, <property>, <value> 형태의 삼중항(triples)로 구성되며, 각 트리플은 독립적인 정보 단위로 처리되며
3. 이 독립 구조(Independence structure)를 활용해, 다음과 같은 장점을 갖고 있습니다.
| 확장성 | 지식 토큰 간 self-attention을 피함으로써, 대규모 KB에 대한 처리 효율 향상 |
| 동적 업데이트 가능성 | 모델 전체를 파인튜닝하지 않아도 KB만 교체하여 새로운 지식 반영 가능 |
| 해석 가능성 향상 | 어텐션 구조를 통해, 어떤 지식이 질문에 활용되었는지 명확하게 파악 가능 |
| 어텐션 기반 리트리벌 기능 | 별도의 검색기(retriever) 없이, 어텐션 메커니즘만으로도 암묵적인 검색 가능 |
| 적은 메모리 자원 사용 | in-context 방식 대비 훨씬 적은 메모리로 유사하거나 더 나은 성능 확보 |
KBLAM은 외부 지식을 dense continuous vectors로 표현하고 이를 LLM에 효율적으로 삽입하는 새로운 프레임워크로, 기존 방식보다 훨씬 확장성 있고 해석 가능한 방법으로 대형 언어 모델에 지식을 통합할 수 있게 합니다. 이 접근은 향후 비정형 텍스트까지 포함한 다양한 지식 통합 시나리오에 활용될 수 있는 가능성을 보여줍니다.
그러나, 아직 연구 단계인 만큼 개선사항이 많은데요. KBLAM은 완전 합성 데이터 기반에서도 강력한 지식 활용 능력을 보이지만, 실제 데이터 일반화, 정보 압축 한계, 추론 다양성 측면에서 개선의 여지가 있습니다. 이를 위해 더 정교한 합성 KB 설계, 정보량 가변화, 멀티홉 추론 등 복잡한 instruction tuning 기법이 향후 발전 방향으로 제안되고 있습니다.
마치며...
간단하게 정리하려고 했는데, 생각보다 글이 길어졌네요. 실무에서 RAG를 활용한 서비스를 구현하면서 늘 가장 고민하는 것이 할루시네이션의 최소화와 응답속도인데, KBLAM은 이 두 문제를 구조적으로 접근한 방식이라는 점에서 굉장히 인상 깊었습니다.
RAG 기반 시스템에서는 관련 정보를 빠짐없이 가져오려면 검색 결과 수를 늘려야 하고, 검증 및 후처리 로직도 필수적으로 따라붙습니다. 하지만 그럴수록 응답속도가 느려지고, 컨텍스트가 길어지면 정확도마저 불안정해지기 마련입니다. 특히 금융과 같이 정확성과 신뢰성이 핵심인 도메인에서는 이 딜레마가 더욱 커지는 것 같습니다.
KBLAM은 이런 고민에 대해 완전히 다른 시각을 제시했는데요, 외부 검색 모듈 없이도 사전 인코딩된 지식 토큰을 활용해 LLM의 각 어텐션 레이어에 정보를 직접 주입하고, 프롬프트 토큰이 지식 토큰을 직접 조회하는 구조를 통해 빠르고 해석 가능한 응답을 생성합니다. 특히, 지식 토큰끼리는 상호작용하지 않고, 프롬프트가 필요할 때만 참조하는 구조 덕분에 지식의 양(M)이 커져도 연산량이 선형적으로 증가해 대규모 KB 확장성도 확보됩니다.
또한, 직사각형 어텐션 구조 덕분에 어떤 지식이 사용되었는지 attention score를 통해 명확하게 추적 가능하고, 무응답 판단 능력도 갖추고 있어 환각 발생을 제어할 수 있다는 점이 실무에서 큰 장점이 될 수 있을 것 같습니다. 저처럼 의도 분기와 조건부 라우팅을 통한 다단계 응답 시스템을 설계할 때에도, KBLAM은 훨씬 간결한 구조로 유사한 목적을 달성할 수 있을 것으로 보입니다. 무엇보다 중요한 점은, KBLAM이 기존 LLM을 재학습하거나 파인튜닝하지 않고도, 소규모 어댑터만 학습하여 지식을 통합할 수 있다는 점입니다. 이는 운영 환경에서의 유연성과 유지관리 효율성 측면에서도 실용적인 이점을 제공할 수 있을 것이라 기대합니다.
앞으로 시간 여유가 있을 때, KBLAM의 구조를 실험적으로 적용해 보고 성능을 테스트해볼 계획입니다. 특히 간단하면서도 정확한 응답이 요구되는 FAQ 시스템이나, 고객 정보 기반의 정형 질의응답처럼, 비교적 작은 범위에서부터 적용해보며 가능성을 탐색해볼 생각입니다. KBLAM이 아직 마이크로소프트의 연구 프로젝트 단계에 있는 만큼, 최신 근황을 꾸준히 팔로우하며 저만의 방향으로 확장해보려 합니다. 긴 글 읽어주셔서 감사합니다.
'RAG' 카테고리의 다른 글
| [RAG] Upstage Document Parse 리뷰 및 테스트 (6) | 2025.03.18 |
|---|---|
| [RAG] TextSplitter 비교 및 중요성 (feat. CharacterTextSplitter, RecursiveCharacterText (1) | 2025.02.06 |
| [RAG] Document Loader 비교 (feat. PDF, Markdown 변환) (7) | 2024.09.11 |
| [RAG] Llama 3.1 프롬프트 형식 (0) | 2024.09.09 |
| [RAG] Perplexity - AI 검색 엔진 리뷰 (feat. ChatGPT 차이점) (5) | 2024.09.09 |