1. 1D convolution vs 2D convolution
CNN(Convolutional Neural Networks)과 1D 컨볼루션의 주요 차이점은 컨볼루션 연산이 적용되는 데이터의 차원성에 있습니다.
CNN이라는 용어는 일반적으로 이미지와 같은 2차원 데이터 또는 때에 따라서는 3차원 데이터(예를 들어, 컬러 이미지의 경우 높이, 너비, 컬러 채널)를 처리하는 네트워크를 가리키는 데 사용되며, 이러한 경우에 주로 2D 컨볼루션 연산이 사용됩니다.
1D convolution
반면, 1D 컨볼루션은 시간적 데이터나 시퀀스 데이터와 같은 1차원 데이터를 처리하는 데 적합하며, 시계열 분석이나 텍스트 분석 그리고 오디오 처리 같은 분야에서 주로 사용됩니다.
여기에서 1차원이란 단일 차원의 벡터가 아닌 합성곱을 위한 커널과 적용하는 데이터의 sequence가 1차원의 모양을 의미합니다. 즉, 데이터가 시간 축이나 하나의 공간 축을 따라 배열되어 있으며, 이에 따라 커널도 동일한 차원에서 데이터를 슬라이드하면서 특징을 추출하는 합성곱 연산을 수행한다는 것을 나타냅니다.
2D convolution
2D 합성곱에서는 가로와 세로 방향으로 이동이 가능한 것은 데이터가 2차원의 격자 구조, 즉 행과 열로 구성되어 있습니다. 이미지와 같은 2D 데이터는 높이와 너비를 가지며, 필터(커널)는 이 두 방향 모두를 고려하여 슬라이딩합니다. 이렇게 가로와 세로, 두 축을 따라 이동하면서 컨볼루션 연산을 수행함으로써, 2차원 이미지의 공간적인 특징을 추출할 수 있습니다.
간단히 말해, 1D 데이터는 한 축을 따라 배열되는 반면, 2D 데이터는 두 축을 따라 공간적으로 배열되며, 이로 인해 2D 컨볼루션은 더 복잡한 공간적 관계와 패턴을 감지할 수 있습니다.
2. 1D Convolution 예제 코드 구현

Using Numpy 1D Convolution
def Conv1D_Numpy(Seq, Kernel):
kernel_size = len(Kernel) # 커널의 길이
Length = len(Seq) # 배열의 길이
output = []
for i in range(Length-kernel_size+1):
conv = np.dot(Seq[i:i+kernel_size], Kernel) # 내적곱
print(Seq[i:i+kernel_size], "*", Kernel, "=> ", conv)
output.append(conv)
output = np.array(output)
return outputdata = np.array([0,3,4,5])
conv1d_filter = np.array([1,2])
output = Conv1D_Numpy(data, conv1d_filter)
output
data(1차원 배열)에 따라 [1,2]의 filter를 한칸씩 이동하며 합성곱을 계산하게 됩니다. 이 때 output은 길이가 3개인 배열([6,11,14])이 나오게 됩니다. (stride = 1)
Using Keras 1D Convolution
# 1D 컨볼루션 모델을 생성하고 컴파일하는 역할을 합니다.
def Conv1D_compile(n_filters, SequenceLength, n_features):
conv_model = tf.keras.Sequential([
tf.keras.layers.Conv1D(filters=n_filters, # 컨볼루션 레이어에서 사용할 필터(커널)의 수입니다.
kernel_size=2,
strides=1,
padding='valid',
input_shape=(SequenceLength, n_features),
use_bias=False, name='c1d')])
conv_model.compile(loss=tf.losses.MeanAbsoluteError(),
optimizer=tf.optimizers.Adam(learning_rate=5e-2))
conv_model.summary()
return conv_modelX = data.reshape((1, data.shape[0], 1)) # -> np.array([0,3,4,5]).reshape(1,4,1)과 동일
y = output.reshape((1, output.shape[0], 1)) # -> np.array([6,11,14]).reshape(1,3,1)과 동일
model_cnn = Conv1D_compile(n_filters=1, SequenceLength=4, n_features=1)

1D Convolution이라고 할지라도, layer의 입력과 출력 데이터는 3차원 이어야합니다.
여기서 (batch, time, feature)의 구조를 가지는데
batch : 샘플 수
time : 입력 데이터의 길이
feature : 데이터셋의 feature 수 (컬러 이미지의 경우 채널이 추가되며 3이 된다.)
그리고 model.summary()를 보면 2개의 params가 존재하는데, 이 두 파라미터가 Conv1D layer의 가중치이고, 훈련을 할수록 kernel값인 1, 2 값에 맞춰질 것입니다.
# 모델을 학습시키고, 특정 에폭마다 모델의 가중치 변화를 추적하여 시각화하는 역할을 합니다.
def Conv1D_Fit_and_PlotWeights(model, X, y, epochs, n_weights, freq=20):
w, loss, mae = [], [], []
for r in range(epochs):
history = model.fit(X, y, verbose=0)
if r%freq==0:
w.append(np.sort(model.layers[0].get_weights()[0].reshape(n_weights))) # 초기 무작위 가중치.
loss.append(history.history['loss'][0])
w = np.array(w)
fig, ax = plt.subplots(figsize=(8,4))
epoch = np.arange(0,len(w))*20 # 매 20번째 epochs마다 모델의 가중치를 추출하고 기록
for n in range(n_weights):
label = "w_{} -> {}".format(n, n+1)
plt.plot(epoch,w[:,n], label=label, linewidth=3)
ax.axhline(n+1, c='gray', linestyle='--')
plt.xlabel("epoch", fontsize=14)
plt.ylabel("weights", fontsize=14)
plt.legend(loc='upper left', bbox_to_anchor=(1., 1.01), fontsize=14)
plt.show()Conv1D_Fit_and_PlotWeights(model=model_cnn, X=X, y=y,
epochs=500, n_weights=2)
두 가중치를 업데이트하면 epoch가 증가할 수록 kernel size인 1과 2로 수렴하는 것을 볼 수 있습니다.
3. 1D Convolution을 사용하는 이유
화자 분리나 음성 인식에서는 발화하는 사람의 목소리가 변할 수 있으며, 이러한 동적 변화를 감지하는 것은 개별 화자를 식별하거나 의미를 해석하는 데 중요합니다.
그렇기 때문에 오디오 신호 처리에서 시간 축에 따라 연속적으로 변화하는 데이터의 특성을 분석하는 것이 중요한데, 1D 컨볼루션이 이 시간 축에 따라 있는 데이터의 패턴을 효과적으로 학습할 수 있습니다.
오디오 신호 처리에 적합한 이유는 다음과 같습니다.
- 특화된 패턴 학습: 1D 컨볼루션은 시간 축에 따른 시퀀스 데이터의 연속적인 특성을 학습하는 데 특화되어 있어, 음성이나 오디오의 시간적인 변화를 더 정밀하게 분석할 수 있습니다.
- 계산 효율성: 1D 컨볼루션은 파라미터의 수가 더 적고 계산적으로 더 효율적이기 때문에, 특히 빠른 처리가 필요한 실시간 오디오 스트리밍과 같은 서비스에서 유리합니다.
- 과적합 방지: 파라미터의 수가 적기 때문에 과적합의 위험이 줄어들며, 특히 데이터 양이 제한적인 상황에서 유리할 수 있습니다.
음악과 같이 더 복잡한 음성 분석 작업에서는 공간 정보(주파수)가 중요한 경우에는 2D 컨볼루션을 사용하는 것이 적합할 수 있으나, 시간 정보만으로 충분하고 실시간 처리가 중요한 경우 1D 컨볼루션을 사용하는 것이 적합하다고 생각합니다.
그러나, 1D convolution에서도 멜 스펙토그램, 스펙토그램과 같은 2차원 데이터 처리가 가능합니다.
2차원 데이터인 멜 스펙토그램이나 스펙토그램을 처리할 때는 각 시간 단계에서의 주파수 대역 특성을 연속적인 시퀀스로 간주하여 1차원 데이터처럼 처리할 수 있습니다.
이는 시간 축을 따라 각 프레임의 주파수 특성을 1D 벡터로 취급하고, 이 벡터들을 연속적인 시퀀스 데이터로 보며 1D 컨볼루션을 적용하는 방식으로 이루어집니다. 이 접근 방식을 통해 시간에 따른 주파수 변화 패턴을 학습할 수 있습니다.
4. 딥러닝 라이브러리 1D Convolution 파라미터 리서치
주요 딥러닝 라이브러리 TensorFlow, Keras, PyTorch에서 1D Convolution의 파라미터를 정리해보겠습니다.
Keras
tf.keras.layers.Conv1D(
filters, kernel_size, strides=1, padding='valid', activation=None,
use_bias=True, kernel_initializer='glorot_uniform',
bias_initializer='zeros', kernel_regularizer=None,
bias_regularizer=None, activity_regularizer=None,
kernel_constraint=None, bias_constraint=None, **kwargs
)tf.keras.layers.Conv1D는 1차원 입력 데이터에 대해 합성곱(convolution) 연산을 수행하는 케라스(Keras) 레이어입니다.
Input Data Shape

Conv1D 레이어는 입력으로 3D 텐서를 받습니다.
형태는 (batch_size, steps, input_dim)과 같으며 자세한 설명은 다음과 같습니다.
batch_size : 데이터 샘플의 수
steps : 시퀀스 길이
input_dim : 각 시퀀스 요소의 차원
input_data.shape이 (1, 4, 1)인 경우, batch_size는 1이고, 이는 한 번에 하나의 데이터 샘플을 처리한다는 것을 의미합니다. 길이가 4인 시퀀스가 2개 있는 경우, 데이터의 형태는 (2, 4, 1)로 바뀌게 됩니다. 이 경우 2개의 시퀀스 샘플을 한 번에 처리할 수 있다는 것을 의미합니다.
Output Data Shape
Conv1D 레이어 출력 데이터 역시 3D 텐서로 받습니다.
형태는 (batch_size, new_steps, filters)로 설명은 다음과 같습니다.
batch_size : 한 번에 처리할 데이터 샘플의 개수
new_steps : 입력 데이터의 길이. (컨볼루션 레이어의 padding과 strides 설정에 따라 결정.) filters : 레이어에 정의된 출력 필터의 수입니다.
출력 데이터는 컨볼루션 연산을 통해 추출된 특징을 포함하며, 각 필터는 입력 데이터에서 다른 특징을 추출하게 됩니다. 따라서, 출력 텐서의 각 차원은 배치 내 샘플 수, 변환된 시퀀스 길이, 그리고 각 위치에서의 필터별 특징의 차원을 나타냅니다.
Return Data Shape
Return 값은 역시 3D tensor로 받으며
다음과 같은 형태 activation(conv1d(inputs, kernel) + bias) 입니다.
Conv1D 레이어는 다음과 같은 매개변수를 가집니다:
- filters: int, 컨볼루션의 필터 수 (즉, 출력 채널의 수).
- kernel_size: int, 필터의 크기
- strides: int, 필터를 이동시키는 간격 (기본값은 1)
- padding: string, ****입력의 패딩 방식을 지정합니다. 기본값인 "valid"는 패딩 없음, "same"은 입력과 출력 크기가 동일하도록 패딩, 즉 padding = ‘same’인 경우 strides =1 출력은 입력과 동일한 크기를 갖습니다. "causal"은 시간 순서를 유지하는 인과 컨볼루션을 의미합니다.
- 1-D convolution에서 causal을 구현하려면 zero padding을 input의 왼쪽 side에만 붙이면 됩니다. (output[t]가 input[t+1:]에 영향을 받지 않게 되므로 컨볼루션 연산에 현재 및 과거의 정보만을 사용하고, 미래의 정보는 사용하지 않습니다. 이를 통해 각 시점의 출력은 해당 시점 이전의 입력 데이터에만 의존하게 되어, 시간에 따른 데이터의 흐름을 모델링할 수 있습니다.) Stride가 1이면 input과 output의 shape이 같으며 Input의 양 side에 padding을 붙이고 합성곱 계산 후에 오른쪽 side를 제거할 수도 있습니다.
- activation: string, 활성화 함수 (기본값은 None) https://www.tensorflow.org/api_docs/python/tf/keras/activations (케라스 activationns 리스트)
- data_format: string, Conv1D 레이어에 입력되는 데이터의 형태를 지정합니다. "channels_last"와 "channels_first" 중 하나를 선택할 수 있으며, 이는 각각 입력 데이터의 차원 순서를 의미합니다. "channels_last"는 입력 형태를 (배치 크기, 스텝 수, 채널 수)로 지정하고, "channels_first"는 (배치 크기, 채널 수, 스텝 수)로 지정합니다. 예를 들어, 오디오 샘플에서 각 스텝은 시간 프레임을 나타내고, 채널은 오디오의 다양한 속성이나 스테레오 오디오의 왼쪽/오른쪽 채널이라고 가정하면 channels_first에서는 각 채널이 먼저 나오고 각 채널 내에서 시간 스텝이 뒤 따릅니다.
- dilation_rate: int or tuple/list, 확장 컨볼루션을 위한 비율을 지정합니다. 확장 컨볼루션에서 사용되며, 컨볼루션 커널의 요소 사이에 삽입되는 공간의 크기를 지정합니다. 이를 통해 커널이 더 넓은 입력 범위를 커버할 수 있게 하면서도 실제로 파라미터 수를 늘리지 않아 계산 효율성을 유지합니다.
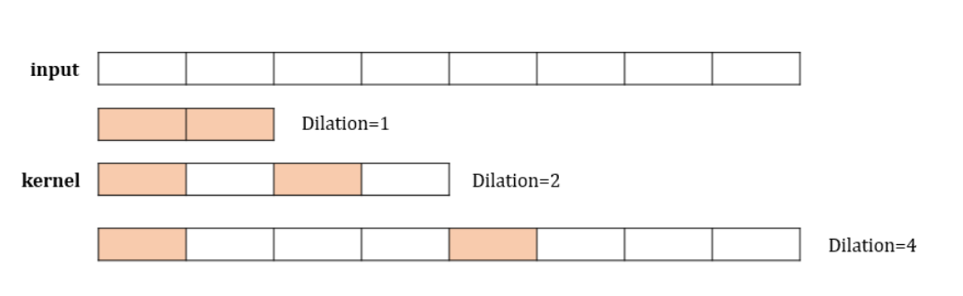
- dilation_rate가 1보다 큰 경우, 커널 요소 사이에 공간이 추가되어 입력 데이터의 더 넓은 컨텍스트를 포착할 수 있습니다. 이는 특히 시계열 데이터 처리나 오디오 처리에서 유용할 수 있습니다.
- dilation_rate를 2로 설정하면, 커널 내 각 요소 사이에 한 칸의 공간이 생깁니다. 예를 들어, 3개의 요소를 가진 커널이 존재하면, 첫 번째와 두 번째 요소 사이, 그리고 두 번째와 세 번째 요소 사이에 각각 한 칸씩 띄워 적용됩니다. 이로 인해 커널이 더 넓은 입력 범위를 커버하면서 더 넓은 컨텍스트의 정보를 포착할 수 있게 됩니다.
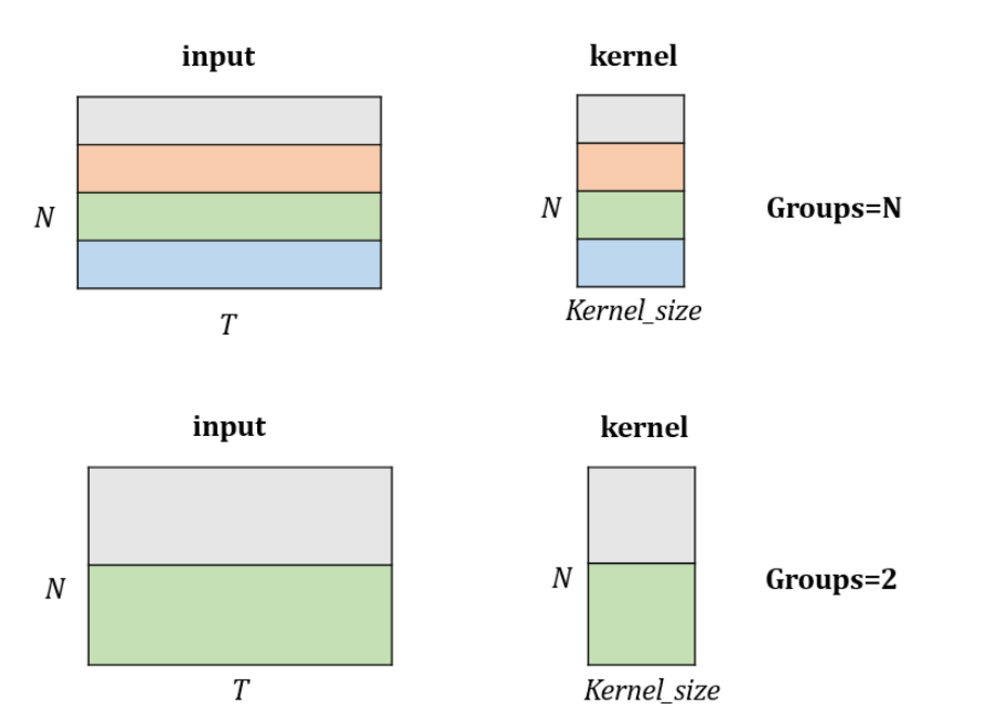
- groups: int, 입력을 채널 축을 따라 분할하는 그룹의 수입니다. groups 파라미터를 사용하는 예시는 입력 채널을 그룹화하여 각 그룹에 대해 독립적으로 컨볼루션을 적용하는 경우입니다. 예를 들어, 입력이 6개의 채널을 가지고 있고, groups=2로 설정하면, 입력 채널이 2개의 그룹(각각 3개 독립적인 채널)으로 나뉘어집니다. 이는 각 그룹이 3개의 채널에서 고유한 특성을 추출하게 만들고, 이러한 독립적인 특성들이 결합됨으로써 모델의 특징 추출 능력을 전체적으로 향상시킵니다.
- use_bias: Boolean, 출력에 바이어스를 추가할지 여부를 나타냅니다. 모델이 입력 데이터가 0일 때도 활성화될 수 있게 하는 것입니다. 이는 모델의 표현력을 향상시켜 주어, 데이터가 가진 패턴을 더 잘 학습할 수 있도록 도우며 일반화 능력을 향상시킬 수 있습니다.
초기화 파라미터
- kernel_initializer: string, kernel 가중치 행렬을 초기화하는 데 사용되는 방법입니다. ‘none’으로 세팅할 시 glorot_uniform이 적용되며, 이는 네트워크의 각 레이어에서 입력과 출력의 크기를 고려하여 가중치를 균일하게 분포시키는 방식입니다. 이 외 방법은 다음 링크 참조https://www.tensorflow.org/api_docs/python/tf/keras/initializers (keras initializer 리스트)
- bias_initializer: string, default = ‘zero’. 바이어스 벡터를 초기화하는 데 사용되는 방법입니다. 신경망의 각 뉴런에 추가되는 바이어스 항의 초기 값을 설정하는 역할을 합니다. 이 초기화는 모델의 학습 시작 시 바이어스 값을 어떻게 설정할지 결정하며, 적절한 초기화는 학습 과정의 효율성과 최종 모델의 성능에 영향을 줄 수 있습니다.
- https://www.tensorflow.org/api_docs/python/tf/keras/initializers (keras initializer 리스트)
규제 파라미터
- kernel_regularizer: 커널 가중치 행렬에 적용되는 규제 함수입니다.
- bias_regularizer: 바이어스 벡터에 적용되는 규제 함수입니다.
- activity_regularizer: 레이어 출력에 적용되는 규제 함수입니다.
- https://www.tensorflow.org/api_docs/python/tf/keras/regularizers (keras regularizer 리스트)
- 3개의 regularzier 모두 값에 규제를 두어 값이 너무 커지거나 작아지는 것을 제한합니다.
제약 파라미터
- kernel_constraint: 커널 가중치에 적용되는 제약 함수입니다.
- bias_constraint: 바이어스 벡터에 적용되는 제약 함수입니다.MaxNorm 제약 조건은 가중치의 L2 노름이 특정 값 이하로 유지되도록 할 수 있으며, 이는 가중치 값이 너무 커져 학습이 불안정해지는 것을 방지합니다. MinMaxNorm는 가중치나 바이어스가 주어진 최소 및 최대 범위 내에 있도록 유지하는데 사용됩니다.
- https://www.tensorflow.org/api_docs/python/tf/keras/constraints (keras constraints 리스트)
- 이들은 신경망의 가중치와 바이어스에 특정 조건을 적용하여, 학습 과정에서 이들이 주어진 조건을 벗어나지 않도록 제한하는 역할을 합니다.
Tensoerflow
tf.nn.conv1d는 TensorFlow에서 제공하는 더 낮은 수준의 1D 컨볼루션 연산으로, tf.keras.layers.Conv1D와 비교하여 더 세밀한 제어가 가능하고 직접적인 텐서 연산을 다루는 데 사용됩니다.
tf.nn.conv1d(
input,
filters,
stride,
padding,
data_format='NWC',
dilations=None,
name=None
)
Input Data Shape
최소 3D 텐서를 받으며, float16, float32, float64 중 하나여야 합니다.
data_foramt = ‘NWC’ : batch_shape + [in_width, in_channels]
data_foramt = ‘NCW’ : batch_shape + [in_channels, in_width]
"NCW"와 "NWC"는 각각 **tf.keras.layers.Conv1D**에서 사용되는 **channels_first**와 **channels_last**와 유사하게 볼 수 있습니다. 여기서 "N"은 배치 크기, "C"는 채널 수, "W"는 너비(데이터 길이)를 의미합니다. "NCW"는 채널이 배치와 너비 사이에 오는 형식이고, "NWC"는 채널이 너비 다음에 오는 형식을 나타냅니다.
Output Data Shape
data_format 파라미터를 통해 입력 데이터의 형태를 "NWC" 또는 "NCW"로 지정하면, 이에 따라 출력 데이터도 같은 형태로 반환됩니다.
data_foramt = ‘NWC’ : batch_shape + [out_width, out_channels]
data_foramt = ‘NCW’ : batch_shape + [out_channels, out_width]
tf.nn.Conv1D는 다음과 같은 매개변수를 가집니다
input : float, 입력 데이터로 최소 3개의 3D 텐서 형태.
filters : 컨볼루션 연산을 수행할 때 사용되는 필터(커널)의 집합을 나타냅니다. 이 파라미터는 최소 3차원 텐서로, [filter_width, in_channels, out_channels]의 형태를 가집니다. 여기서 **filter_width**는 필터의 길이, **in_channels**는 입력 데이터의 채널 수, **out_channels**는 출력 데이터의 채널 수(즉, 필터의 수)를 의미합니다. 이를 통해 입력 데이터에 여러 필터를 적용하여 다양한 특징을 추출할 수 있습니다. input과 filter의 Height(dimension), channel값이 같다.
stride : int, 필터가 오른쪽으로 이동하는 칸의 수. data_format : string, ‘NWC’ or ‘NCW’
dilations : int, 파라미터는 입력의 각 차원에 대한 확장 인자를 지정합니다. 기본값은 1이며, k>1로 설정하면, 각 필터 요소 사이에 k-1개의 셀이 건너뛰어집니다. 이는 필터가 입력 데이터의 더 넓은 영역을 커버할 수 있게 하여, 더 넓은 컨텍스트의 정보를 포착할 수 있도록 합니다. name : 작업 이름으로 선택사항입니다.
Pytorch
import torch.nn as nn
nn.Conv1d(in_channels=4, out_channels=64, kernel_size=5, stride=3,
padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
Input Data Shape
input은 keras, tensorflow와 동일한 3D 텐서로 받습니다.
형태는 [Batch_size, Feature_dimension, Time_step] 입니다.
time step(K) 마다 feature dimension(N)이 존재하는 2차원 배열이 들어온다. batch size(B)까지 고려하면 3차원이지만 알아서 계산해줍니다.
주요 파라미터는 다음과 같습니다.
in_channels: input의 feature dimension (입력 데이터의 채널 수 )
out_channels: 내가 output으로 내고싶은 dimension (필터의 수, 생성될 출력 데이터의 채널 수)
kernel_size: time step을 얼마만큼 볼 것인가(=frame size = filter size)
stride: kernel을 얼마만큼씩 이동하면서 적용할 것인가 (Default: 1)
dilation: kernel 내부에서 얼마만큼 띄어서 kernel을 적용할 것인가 (Default: 1)
padding: 한 쪽 방향으로 얼마만큼 padding할 것인가 (그 만큼 양방향으로 적용) (Default: 0)
groups: kernel의 height를 조절 (Default: 1)
bias: bias term을 둘 것인가 안둘 것인가 (Default: True)
padding_mode: 'zeros', 'reflect', 'reflect', 'replicate', 'circular' (Default: 'zeros')
5. 음성 데이터 1D Convolution 적용 코드 예제
1초 분량의 8000HZ 음성 Conv 1D 적용 전 후
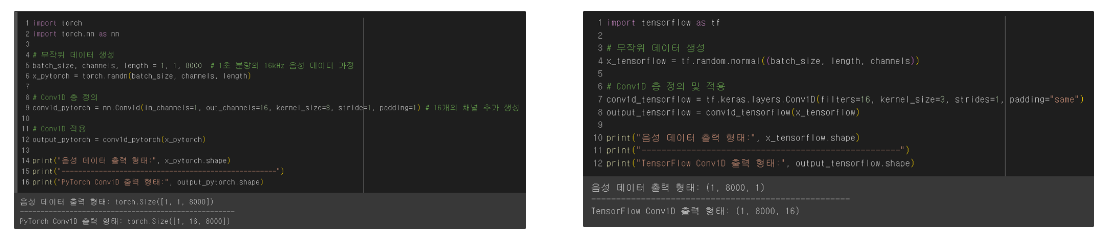
Keras Conv 1D 적용 전 : Keras 입력 데이터 형태는 (batch_size, 1, 8000)입니다.
Keras Conv 1D 적용 후: 출력 데이터 형태는 (batch_size, 16, 8000)가 됩니다. 여기서 8000은 입력 길이가 변하지 않았으며(패딩='same'), 16는 적용된 필터의 수로, 출력 채널의 수를 의미합니다.
Pytorch의 출력 결과는 동일하나 input data의 length와 channels의 위치가 바꼈습니다.
실제 12초의 WAV 파일로 멜 스펙토그램 변환
import librosa
import numpy as np
import matplotlib.pyplot as plt
file_path = './12_test.wav'
# 12초 길이의 8000Hz 샘플링 레이트 음성 데이터 로드
y, sr = librosa.load(file_path, sr=8000, duration=12)
# 멜 스펙트로그램을 계산.
mel_spectrogram = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128, hop_length=256, n_fft=512)
mel_spectrogram_db = librosa.power_to_db(mel_spectrogram, ref=np.max)
# 멜 스펙트로그램의 형태를 확인.
print(mel_spectrogram_db.shape) # (128,376)
# 멜 스펙트로그램을 시각적으로 그립니다.
plt.figure(figsize=(10, 4))
librosa.display.specshow(mel_spectrogram_db, sr=sr, hop_length=256, x_axis='time', y_axis='mel')
plt.colorbar(format='%+2.0f dB')
plt.title('Mel Spectrogram')
plt.tight_layout()
plt.show()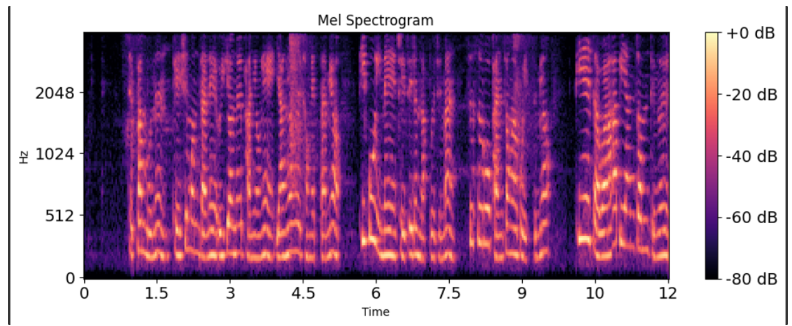
여기서 mel_spectrogram_db.shape은 (128,376)이 나오게 되는데, 이는 오디오 파일의 길이(12초)와 샘플링 레이트(8000) 그리고 hop_length, n_fft 파라미터 때문입니다.
첫 번쨰 차원은 n_mels 멜 스펙토그램의 bin 수 입니다.
- shape의 첫 번째 차원인 128은 n_mels 파라미터에 의해 결정되는 멜 빈(bin)의 수입니다. 이 경우 128개의 멜 빈을 사용했습니다.
두 번째 차원은 시간 축을 따라 계산된 프레임의 수입니다.
- hop_length=256: 오디오 신호의 연속하는 프레임 사이에서 256개의 샘플 만큼 이동하겠다는 것을 의미합니다. 샘플링 레이트가 8000Hz이기 때문에 1초에 8000개의 샘플이 있고, hop_length에 따라 약 31.25ms (256/8000) 간격으로 이동하며 멜 스펙트로그램을 계산합니다. 실제 데이터에선 12초 동안 8000Hz 샘플링으로 총 96,000개의 샘플이 존재하므로 96000/256로 계산할 수 있습니다.
- n_fft=512: 각 프레임의 Fast Fourier Transform(FFT)를 계산할 때 512개의 샘플을 사용하겠다는 것을 의미하며, 이는 주파수 해상도를 결정합니다. 그러나 첫 번쨰 프레임이 0번째 샘플에서 시작하므로 ((96000-512)/256) +1이 됩니다ㄱ
그 결과, (128,376) shape이 나오게 됩니다.
멜 스펙토그램 변환한 음성 데이터 1D Covoultion 적용
mel_spectrogram_tensor = torch.tensor(mel_spectrogram_db[np.newaxis, :], dtype=torch.float)
# 컨볼루션 레이어 정의
conv1d_layer = nn.Conv1d(in_channels=128, out_channels=32, kernel_size=3, stride=1, padding=1) # in_channels = input 데이터 채널의 수
# 레이어에 멜 스펙트로그램 텐서를 적용합니다. PyTorch는 (batch, channels, length) 형태를 입력해야 합니다.
# 우리의 데이터는 (1, 128, length) 형태로, 128은 멜 빈의 수, length는 시간 축에 대한 길이입니다.
conv_output = conv1d_layer(mel_spectrogram_tensor)
# 결과의 형태를 출력합니다.
print('Conv1d Output Shape:', conv_output.shape) # torch.Size([1, 32, 376])
# 멜 스펙트로그램을 시각적으로 그립니다.
plt.figure(figsize=(10, 4))
librosa.display.specshow(mel_spectrogram_db, sr=sr, hop_length=256, x_axis='time', y_axis='mel')
plt.colorbar(format='%+2.0f dB')
plt.title('Mel Spectrogram')
plt.tight_layout()
plt.show()
출력 결과, torch.Size([1, 32, 376])사이즈가 나오게 됩니다.
conv1d_layer는 128 채널의 입력을 받아 32 채널의 출력을 생성하는 1D 컨볼루션 레이어입니다.
kernel_size=3, stride=1, padding=1은 입력 길이를 유지합니다. 따라서 출력 텐서의 length는 멜 스펙트로그램의 length와 동일하며, 채널 수는 32로 변경됩니다.
conv_output 텐서의 형태는 출력 채널 수를 제외하고 멜 스펙트로그램의 입력 형태와 같아야 합니다.
멜 스펙토그램 변환한 음성 데이터 1D Covoultion + groups 파라미터 적용
# groups 추가
conv1d_layer = nn.Conv1d(in_channels=128, out_channels=32, kernel_size=3, stride=1, padding=1, groups=4)
# 레이어에 멜 스펙트로그램 텐서를 적용합니다.
conv_output = conv1d_layer(mel_spectrogram_tensor)
# 결과의 형태를 출력합니다.
print('Conv1d Output Shape with groups=4:', conv_output.shape)출력 결과, groups를 추가하지 않은 예제와 동일하게 torch.Size([1, 32, 376])사이즈가 나옵니다.
groups 매개변수를 nn.Conv1d 레이어에 추가하면, 입력 채널과 출력 채널이 그룹으로 나뉘어져 독립적인 컨볼루션 연산을 수행하게 됩니다. 이 때 in_channels과 out_channels는 groups로 나누어떨어져야 합니다.
in_channels=128, out_channels=32로 설정하고 groups=4을 추가한다면, 실제로는 각 그룹에 32개의 입력 채널과 8개의 출력 채널이 할당됩니다.
각 그룹은 해당하는 입력 채널 부분집합에 대해서만 컨볼루션을 수행하고, 각각의 결과는 병합되어 최종 출력을 생성합니다.
따라서, groups=4를 설정하는 경우, 전체 128개의 입력 채널이 4개의 독립된 컨볼루션 연산으로 나뉘어 처리되며, 각 그룹이 8개의 출력 채널을 생성합니다.
그 결과는 여전히 32개의 출력 채널을 가질 것이지만, 각 그룹의 8개의 채널은 오직 해당 그룹의 입력 채널에만 연산을 수행하게 됩니다.
1D Convolution + groups를 응용하여 Depthwise Convolution 생성
# Depthwise 컨볼루션을 위한 Conv1d 레이어 정의
# 입력 채널 수와 출력 채널 수가 동일하고, groups가 in_channels와 같습니다.
conv1d_layer_depthwise = nn.Conv1d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1, groups=128)
# 레이어에 멜 스펙트로그램 텐서를 적용합니다.
conv_output_depthwise = conv1d_layer_depthwise(mel_spectrogram_tensor)
# 결과의 형태를 출력합니다.
print('Depthwise Conv1d Output Shape:', conv_output_depthwise.shape)
출력 결과, torch.Size([1, 128, 376])사이즈가 나오게 됩니다.
groups를 입력 채널의 수(in_channels)와 같게 설정합니다. 그리고 출력 채널의 수(out_channels)도 입력 채널의 수와 같아야 합니다.
이렇게 설정하면, 각 입력 채널에 대해 하나의 컨볼루션 필터가 적용되어 depthwise 컨볼루션을 수행할 수 있습니다.
Depthwise 컨볼루션을 사용하는 경우, in_channels와 out_channels는 동일해야 하고, groups의 값도 in_channels와 동일해야 합니다.
6. 마치며...
음성 데이터 처리를 위해 1D Convoultion에 대해 자세히 알아봤습니다.
'DL > Voice' 카테고리의 다른 글
| [Voice] 딥러닝 음성 처리 파이썬 실습 - 16K / 8K 비교, 음성 데이터 연산 (0) | 2024.06.12 |
|---|---|
| [Voice] 디지털 신호(음성) 처리 개념 정리 (3) - 16 Bit, 44.1 kHz / PCM (1) | 2024.06.12 |
| [Voice] 디지털 신호(음성) 처리 개념 정리 (2) - 나이퀴스트 이론 / 앨리어싱 현상 (0) | 2024.06.12 |
| [Voice] CNN (Convolutional neural network) 간단 설명 (4) | 2024.03.12 |
| [Voice] 디지털 신호(음성) 처리 개념 정리 (2) | 2024.03.12 |