
ChatGPT o1 vs DeepSeek R1
DeepSeek R1 모델이 ChatGPT o1 모델보다 월등히 적은 비용으로 유사한 성능을 보여 이슈가 되고 있습니다.
그렇다면 두 모델은 어떠한 차이가 있는지 DeepSeek를 기준으로 비교 해보겠습니다.
DeepSeek 모델의 자세한 아키텍처와 학습 방식은 추후에 V3, R1 논문 리뷰 글을 작성하도록 하겠습니다.
1. 모델 아키텍처
ChatGPT o1
- 구조 : 기본적으로 Transformer 아키텍처를 사용하며, 다중 헤드 어텐션과 은닉층을 통해 복잡한 문맥 관계를 모델링합니다.
- 추론 비공개 : 내부적으로 체인-오브-쏘트(chain-of-thought) 방식이 적용되지만, 사용자에게는 그 과정을 숨기는 방식으로 설계되어 있어 최종 답변만 제공됩니다.
DeepSeek R1

- 구조 : MoE(전문가 혼합, Mixture of Experts) 및 다중 헤드 잠재주의(MLA)와 같은 기법을 활용해 효율성과 확장성을 극대화했습니다.
- 추론 공개 : DeepSeek R1은 체인-오브-쏘트 과정을 사용자에게 노출하는 특징이 있어, 모델이 문제를 어떻게 풀어가는지 투명하게 확인할 수 있습니다.
2. 학습 방식
ChatGPT o1 모델
- 지도학습(Supervised Fine-Tuning, SFT) + 인간 피드백 강화학습(RLHF):
ChatGPT o1은 대규모 인간 라벨링 데이터를 이용한 지도학습으로 기본 능력을 갖춘 후, 인간 평가자의 피드백을 반영하는 강화학습(RLHF)을 통해 출력의 품질, 안전성, 그리고 사용자의 요구에 맞는 응답을 생성하도록 조정합니다.
DeepSeek R1 모델
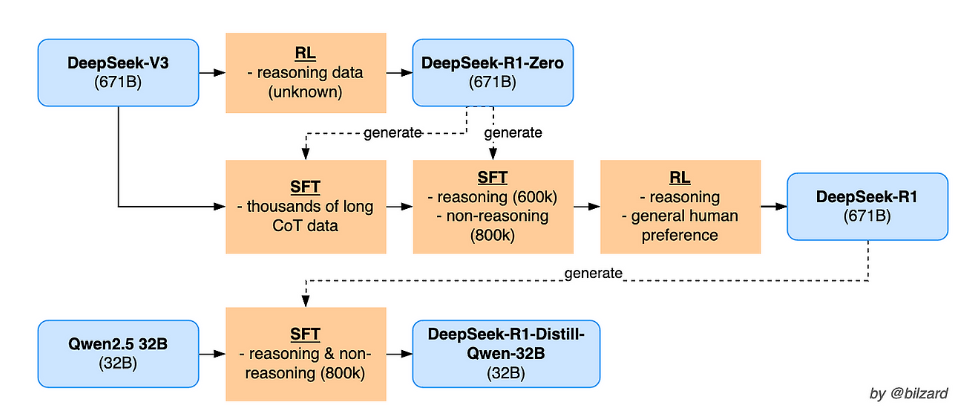
DeepSeek-R1은 먼저 DeepSeek-V3-Base라는 기반 모델을 사용하여 여러 단계를 거쳐 강화학습(RL)과 Supervised Fine-Tuning(SFT)을 통해 추론 능력을 극대화하는 과정을 진행합니다.
1. 초기 SFT 단계 : 콜드 스타트 데이터를 이용해 DeepSeek-V3를 SFT로 미세 조정하여 모델의 기초 추론 패턴을 학습.
2. 강화학습 1단계 : GRPO 기반의 강화학습을 통해 모델이 스스로 더 깊은 추론을 할 수 있도록 보상 함수를 활용해 추가 훈련. 이 과정에서 DeepSeek-R1-Zero와 같이 순수 강화학습만 사용한 버전도 존재함.
3. SFT 데이터 합성 및 추가 : 내부 모델(강화학습을 거친 모델)을 이용하여 수십만 건의 합성 reasoning 데이터와 non-reasoning 데이터를 생성한 후, 이를 기반으로 다시 SFT를 진행해 모델의 출력 품질과 일관성을 개선.
4. 강화학습 2단계 : 최종적으로 모든 시나리오에 대응하는 RL을 적용하여 DeepSeek-R1 모델을 생성.
차이점
지도 데이터와 인간 피드백 사용 여부:
- ChatGPT o1: 대규모 지도 데이터와 인간 피드백(RLHF)에 크게 의존하여, 안전성과 응답의 품질을 높입니다.
- DeepSeek R1: 초기 SFT 단계가 존재하긴 하지만, 주로 순수 강화학습과 규칙 기반 보상으로 모델이 스스로 학습하게 하여, 인간의 직접 개입을 최소화합니다.
증류를 통한 모델 경량화:
- ChatGPT o1: 전통적으로 거대 모델을 그대로 서비스하는 방식.
- DeepSeek R1: 증류 과정을 통해 고성능 Teacher 모델의 지식을 경량화된 Student 모델로 전이시킴으로써, 비용과 자원 효율성을 크게 높인 증류 모델도 함께 공개했습니다. (DeepSeek-R1-Distill-Qwen-32B, DeepSeek-R1-Distill-Llama-70B...)
3. 보안성
ChatGPT o1 모델
- 보안 정책: OpenAI는 미국 및 영국의 AI 안전 가이드라인에 따라 체계적인 보안 기준을 따르므로 보안성이 중요한 프로젝트에서 유용합니다.
- 데이터 관리: 다양한 규제 기관과 협력하며, 사용자 데이터 보호와 악의적 사용 방지를 위한 모니터링 체계를 갖추고 있습니다.
DeepSeek R1 모델
- 검열 및 제한: 중국 정부의 요구에 따라 민감한 정치적 주제에 대해 엄격한 검열 및 응답 제한이 적용됩니다.
- 데이터 관리: 사용자의 데이터는 중국 내 서버에 저장되므로, 일부 사용자나 기업에서는 데이터 프라이버시 측면에서 우려가 있습니다. 단, 이는 로컬 모델을 활용해 해결할 수 있습니다.
4. 비용 비교
ChatGPT o1 모델
- 비용 구조: OpenAI의 o1 모델은 높은 학습 및 추론 비용으로 인해 구독 기반으로 제공되며, 토큰 당 비용이 상대적으로 높습니다.
DeepSeek R1 모델
- 경제성: DeepSeek R1은 같은 수준의 성능을 제공하면서도, 입력 토큰 100만 개당 0.14달러, 출력 토큰은 2.19달러 정도로, OpenAI 모델에 비해 매우 저렴한 비용으로 제공됩니다.
- 오픈소스: 모델 가중치(weights)가 공개되어 있어, 기업들이 자체 서버에 설치하거나 커스터마이징할 수 있다는 장점이 있습니다.
5. 성능 및 벤치마크

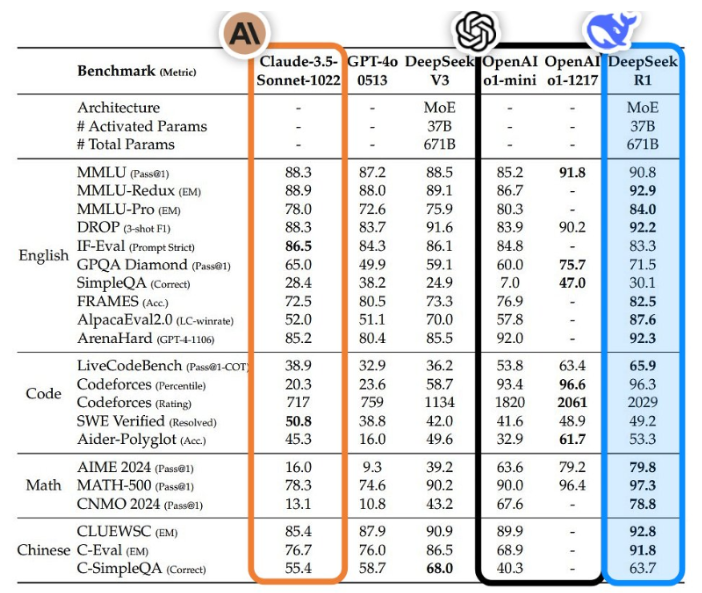
- 벤치마크 비교:
- 두 모델 모두 자연어 처리, 코딩, 수학, 복잡한 추론 문제 등 여러 벤치마크에서 유사한 점수를 기록했습니다.
- DeepSeek R1은 일부 코딩 및 수학 문제에서 더 나은 점수를 보이기도 하며, 체인-오브-쏘트의 투명성 덕분에 문제 해결 과정을 명확히 보여줍니다.
- ChatGPT o1은 자연어 처리와 같은 일반적인 작업에서 다소 안정적이고 균형 잡힌 답변을 제공하는 경향이 있습니다.
6. 각 모델의 장점 정리
ChatGPT o1의 장점:
- 안정성과 신뢰성: 오랜 기간 다듬어진 기술과 엄격한 보안, 안전 가이드라인을 통해 사용자에게 신뢰할 수 있는 서비스를 제공합니다.
- 풍부한 부가 기능: 음성 모드, 이미지 생성, Canvas 편집, 기억 기능 등 다양한 기능을 갖추고 있어 다각도의 활용이 가능합니다.
- 균형 잡힌 응답: 민감한 주제에 대해 신중하고 균형 잡힌 답변을 제공합니다.
DeepSeek R1의 장점:
- 비용 효율성: 동일한 수준의 성능을 훨씬 낮은 비용으로 제공하며, 예산에 민감한 사용자나 기업에 유리합니다.
- 오픈소스 및 커스터마이징: 모델 가중치가 공개되어 있어, 직접 설치하거나 커스터마이징하여 내부 시스템에 통합할 수 있습니다.
- 투명한 추론 과정: 체인-오브-쏘트 방식의 추론 과정을 노출하여, 개발자들이 모델의 문제 해결 과정을 이해하고 개선할 수 있는 기회를 제공합니다.
결론
두 모델은 각각 고유의 강점과 특징을 가지고 있으며, 사용 목적과 환경에 따라 선택이 달라질 수 있습니다.
- 안정성과 다기능성이 중요한 환경에서는 ChatGPT o1이 유리하며,
- 비용 절감과 커스터마이징, 그리고 투명한 추론 과정을 중시하는 경우에는 DeepSeek R1이 매력적인 대안이 될 수 있습니다. 단, 보안성 이슈가 있어서 로컬 환경에서 모델을 실행시키는 등의 방법을 사용하시는 것을 권장드립니다.
지금까지 오픈소스 중에 ChatGPT o1의 유사한 성능을 내는 모델이 존재하지 않았는데, DeepSeek R1모델이 오픈소스로 공개되면서 개인 사용자 또는 기업에서도 ChatGPT o1 수준의 모델을 커스터마이징하여 내부 AI 서비스를 개발할 수 있게 됐습니다.
이로 인해, 여러 소규모 집단에서도 도메인에 특화된 기존보다 더 고도화된 AI 서비스를 개발할 수 있을 것이라 기대하고 있습니다. DeepSeek R1의 오픈소스 공개는 폐쇄된 AI 시장에서 큰 전환점이 될 수 있을 것이라 생각합니다.
Qwen-2.5-Max가 오픈소스로 공개되며, OpenAI o3-mini 무료 제공 그리고 Deep Research 공개와 같이 AI 시장의 경쟁이 더 심화되고 있기에 변화하는 트렌드를 팔로잉 하는 것이 중요할 듯 합니다.
'AI Tech' 카테고리의 다른 글
| [AI] 딥시크 이후, 2025년 1~2월 최신 LLM 이슈 요약 (Gemini, DeepSeek, ChatGPT, Qwen) (0) | 2025.02.05 |
|---|---|
| [AI] 오픈소스 모델 DeepSeek R1 요약 (0) | 2025.02.03 |
| [AI Tech] AICC(컨텍센터)에서 인바운드와 아웃바운드란? (2) | 2024.02.14 |
| [AI Tech] chatGPT API 사용방법 feat. Python (1) | 2024.02.14 |
| [AI Tech] AICC 아키텍처, VoIP Infra, AI 시스템 구성. (4) | 2024.02.13 |