https://mz-moonzoo.tistory.com/5
[ML]AutoML 소개 및 실습(feat.pycaret, H2O, TPOT, LightAUTOML)(1)
1. INTRO AutoML(Automated Machine Learning)은 자동화된 Machine Learning(자동화된 ML 또는 AutoML이라고도 함)은 시간 소모적이고 반복적인 기계 학습 모델 개발 작업을 자동화하는 프로세스입니다. 데이터 과학
mz-moonzoo.tistory.com
1장에 이어서 작성해보도록 하겠습니다.
실습 깃허브 코드
GitHub - moonjoo98/DACON: 2021~2022년에 참여한 DACON 공모전 정리입니다.
2021~2022년에 참여한 DACON 공모전 정리입니다. Contribute to moonjoo98/DACON development by creating an account on GitHub.
github.com
2-3. LightAutoML
https://github.com/sberbank-ai-lab/LightAutoML
GitHub - sberbank-ai-lab/LightAutoML: LAMA - automatic model creation framework
LAMA - automatic model creation framework. Contribute to sberbank-ai-lab/LightAutoML development by creating an account on GitHub.
github.com
지금까지 진행한 pycaret, h2o에 비해 비교적 더 짧은 코드로 실습을 진행해봤습니다.
LightAutoML이 가장 짧게 코드를 작성할 수 있다는 것은 아닙니다.
2-3-1. 데이터 및 파라미터 세팅
우선 가장먼저 데이터를 불러오는것이 필요합니다. test 데이터의 컬럼만 일부 잘라준 이유는 trainㄷ데이터는 뒤에서 roles이라는 파라미터를 통해 전처리를 진행해주기 때문입니다.


사용하고자 하는 metric을 직접 정의도 가능합니다. 여기 실습에서는 사용하지 않고 Task()함수를 통해 설정을 진행했습니다.
Task()
Task()함수부터 살펴보면 예측하고자 하는 label이 A,B,C로 3개이므로 'multiclass'로 지정해줬습니다.
loss와 metric에는 평가하고자하는 metric으로 적절하게 선택해서 진행하면 되겠습니다. 저는 대회의 평가지표가 f1이기 때문에 f1으로 세팅하고 진행했습니다.
roles
roles는 학습시에 train데이터 전처리를 위해 role을 설정 해주는 것입니다. target 키 값에 value 값으로 예측하고자 하는 컬럼명인 class로 입력해줬습니다. drop은 컬럼에서 필요없는 컬럼명을 입력하면 제거 해줍니다.
2-3-2. Model Train
지금까지 진행하면서 이 library를 가장 쉽게 구현한 것 같습니다. 딱히 이게 더 쉬워서 그런 것은 아닌데 여러가지 파라미터를 뜯어보지 않아서 그런것 같기도합니다.

앞서 설정해둔 파라미터를 그대로 입력 해주도록합니다. 파라미터에 대한 설명은 맨 처음 사진에 주석에 달려있으니 참고하시면 될 것 같습니다.
그렇게 설정해둔 파라미터로 model을 세팅해주시면 fit_predict를 진행하시면 됩니다. fit_predict() 함수 안에는 train 데이터셋을, roles에는 앞서 설정해둔 roles를 그대로 넣어주시면 됩니다. Timeout을 300으로 설정해뒀기 때문에 지금까지 진행한 library중 가장 빠르게 학습이 완료됐습니다.
2-3-3. Model Predict
추론하는 것 역시 모든 AutoML libaray 처럼 간단하게 진행하실 수 있습니다.
automl.predict()안에 예측하고자 하는 test데이터셋을 넣어주시면 바로 추론이 시작됩니다.
test데이터셋은 train과 똑같은 형식으로 전처리를 해주시고 넣어주시면 됩니다.

LightAutoML은 다른 library과 다르게 확률값으로 예측값을 제공합니다. 그렇기 때문에 np.argmax()를 통해 가장 확률이 높은 값으로 라벨을 뽑아내주시면 train부터 predict까지 끝이 났습니다.
2-3-4. Leaderboard score

h2o automl과 같은 성능을 기록하고 있네요. train 데이터도 적고 test 데이터도 적기 때문에 같은 score가 나온 것 같습니다. 서로 다른 모델이 이기 때문에 private score는 서로 다르게 나올 것입니다.
여기까지 lightautoml에 대한 소개를 마치도록 하곘습니다.
2-4. TPOT
http://epistasislab.github.io/tpot/
TPOT
Home Consider TPOT your Data Science Assistant. TPOT is a Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming. TPOT will automate the most tedious part of machine learning by intelligently exploring th
epistasislab.github.io
TPOT은 사용이 매우 간편합니다. 그러나 높은 성능을 얻으려면 그만큼 많은 시간이 걸립니다.
또한 TPOT은 같은 데이터 셋이더라도 다른 결과를 낼 수 있습니다. TPOT의 최적화 기법이 확률적이기 때문에 랜덤성이 있기 때문입니다. 사실 이 점을 이용해 기존에 생각했던 모델 말고도 해당 데이터셋에 적합한 모델을 찾는데에 유용합니다.
현재까지 leaderboard 결과 가장 좋은 score를 기록중인 automl library입니다. 사실 다른것들이 안좋아서보다는 TPOT library를 10시간이상 돌려서 그런것 같기도 합니다. 그럼 마지막으로 TPOT 실습을 진행해보도록 하겠습니다.
2-4-1. 데이터 전처리

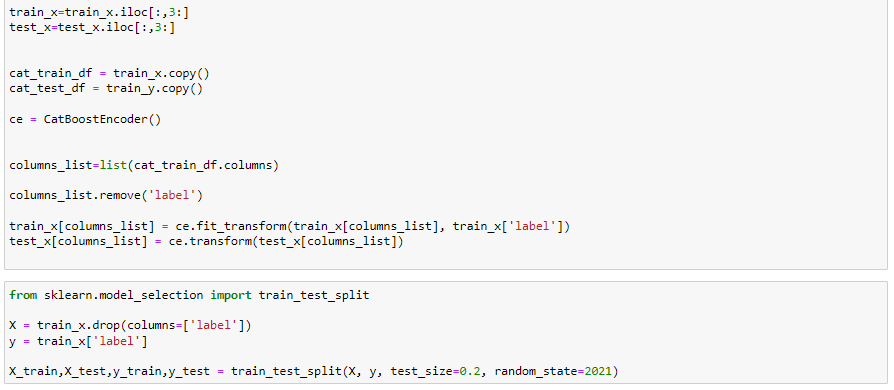
우선 학습을 위해 데이터셋 전처리를 진행해줬습니다. 필요없는 컬럼을 제거해주고 변수와 예측하고자 하는 target에 라벨 인코딩을 진행해줬습니다. 제가 실수 했던 것일수도 있지만 tpot은 기존 library처럼 자동으로 인코딩을 진행해주지는 않는것 같습니다.
그리고 CatBoostEncoder를 활용해 컬럼들을 한번더 변환해줬습니다. 사실 캣부스트인코더를 사용하지 않고 그대로 사용하셔도 무방할 것입니다. 그리고 학습을 위해 train_test_split을 통해 데이터셋을 split해줬습니다.
2-4-2. Model Train
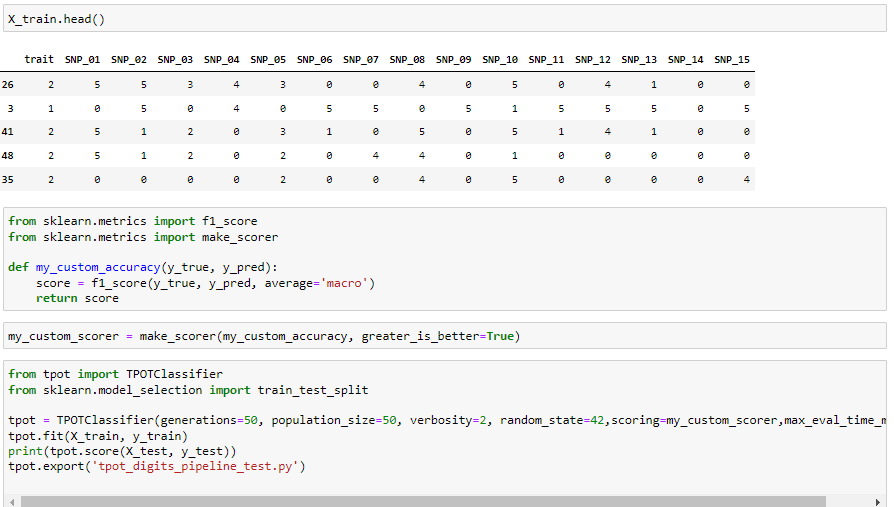
이제 데이터 전처리를 완료했으니 바로 모델 학습으로 넘어가보도록 하겠습니다. 우선 tpot에서도 custom_score를 사용할 수 있습니다. 사용하고자 하는 평가지표를 my_custom_accuracy처럼 만들어서 sklearn이 make_scorer을 통해 만들어 주시고 모델 파라미터에 넣어 주시면 됩니다.
대표적인 파라미터 몇 개만 설명해보도록 하겠습니다. 이 외에도 여러 파라미터가 있으니 확인해보면 좋을 것 같습니다.
파라미터
- generations (default=100): 몇 세대에 걸쳐서 모델을 탐색할지 결정합니다. tpot 모델이 돌아가는 시간을 결정하는 가장 중요한 파라미터중 하나입니다. 클수록 높은 성능의 모델을 찾을 확률이 높습니다. None으로 입력하면 이후 나오는 max_time_mins에 의해 결정됩니다.
- population_size (default=100): 매 generation마다 남겨놓을 pipeline의 수를 설정합니다. 클수록 높은 성능의 모델을 찾을 확률이 높습니다.
- offspring_size (default=None): 매 generation마다 생성할 자손의 수입니다. default로 설정하면 population_size로 설정됩니다.
TPOT은 위의 세가지 파라미터로 총 generations * offspring_size + population_size 개의 pipeline을 평가합니다.
- scoring (default='neg_mean_squared_error') : pipeline을 평가할 지표를 설정합니다. 내장 metric은 'neg_median_absolute_error', 'neg_mean_absolute_error', 'neg_mean_squared_error', 'r2'가 있으며, sklearn의 make_scorer 모듈로 custom metric을 정의할 수도 있습니다.
- cv (default=5) : cross-validation 전략을 설정합니다. 정수로 주면 정수만큼의 KFold를 시행합니다. cv generator 객체나 train/test split 리스트가 주어지면 해당하는 전략대로 cv를 시행합니다.
- subsample (default=1.0) : tpot 과정에서 학습시킬 데이터의 비율을 결정합니다. subsample=0.5는 tpot이 training data의 절반을 랜덤 하게 추출해 학습한다는 것입니다. 이 subsample은 pipeline이 진행되는 동안 그대로 유지됩니다.
- max_time_mins (default=None): 하나의 pipeline을 최적화하는데 드는 시간(분)을 설정합니다. 여기서 설정한 시간을 초과하면 그냥 넘어갑니다.
- max_eval_time_mins (default=5): 하나의 pipeline을 평가하는데 드는 시간(분)을 설정합니다. 크게 설정할수록 tpot이 좀 더 복잡한 pipeline을 평가할 수 있습니다.
- random_state (default=None): 랜덤 인자입니다. 특정 랜덤 변수를 그대로 쓰고 싶을 때 원하는 숫자를 입력하시면 됩니다. 항상 지정하는 것이 좋습니다.
- config_dict: 특정 모델이나 파라미터를 쓰고 싶을때 설정하는 파라미터입니다. 내장 configuration을 사용하고 싶으면 'TPOT light'(가볍고 빠른 모델 사용), 'TPOT MDR'(MDR을 이용한 최적화), 'TPOT sparse'(sparse한 데이터 셋에 좋은 모델들) 중 하나를 사용하면 됩니다. 직접 필요한 operator와 모델을 쓰고 싶으면 custom configuration dictionary를 만들어 설정해주면 됩니다.
- use_dask (default=False) : dask를 이용해 기존에 학습했던 estimator를 또 학습하는 것을 피합니다. 학습시간을 단축 시킬 수 있습니다.
- early_stop (default=None) : 더이상 성능 향상이 안 되는 generation의 한계 수를 정하고, 한계치를 넘어가면 학습을 중지합니다.
모델 학습이 종료되면 다음과 최적의 파이프라인을 py파일로 저장할 수 있습니다. 여기서 모델부분을 손쉽게 가져와서 사용할 수 있습니다.
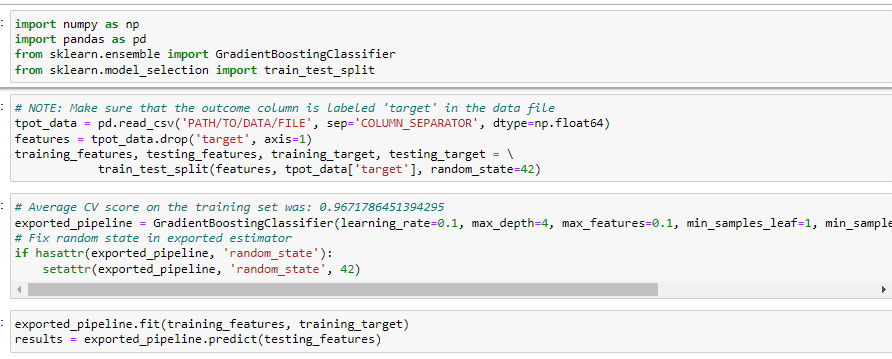
2-4-3. Model Predict
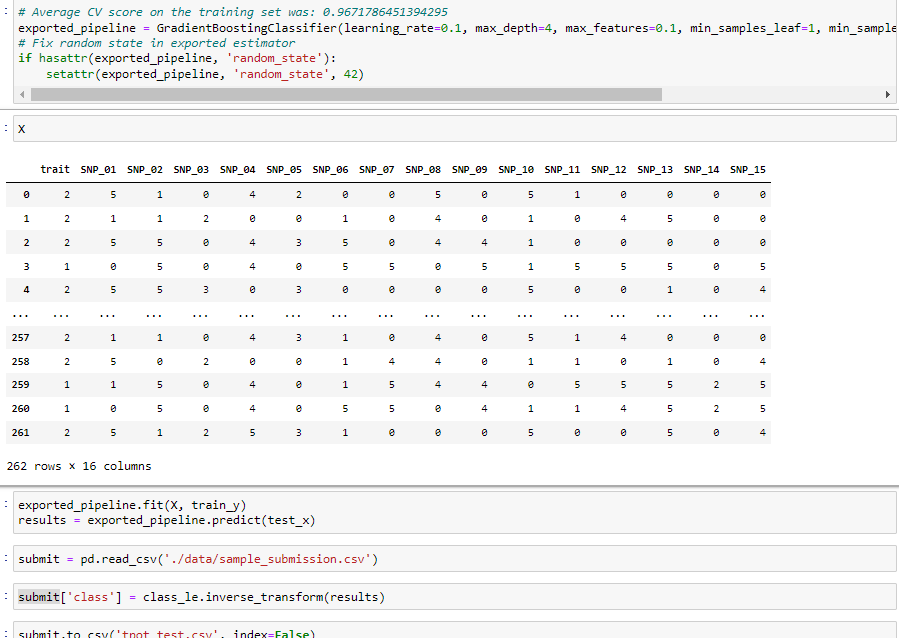
최적의 파이프라인을 가져와 원하는 데이터로 다시 학습을 시키고 predict해봤습니다. 데이터가 너무 적기 때문에 전체 데이터를 활용해 validation없이 학습을 진행하고 추론해봤습니다. 이 후 앞서 사용한 라벨인코더를 통해 target값을 inverse_transform()을 통해 다시 A,B,C로 변환을 진행해주고 submission파일을 만들었습니다.
2-4-4. Leaderboard score


보시는 것처럼 오랜 시간동안 최적의 파이프라인을 탐색할 시 더 좋은 성능의 파이프라인을 찾아내는 것을 확인하실 수 있습니다. 여러가지 파라미터를 건드리면서 최고의 성능을 뽑아내시길 바랍니다.
3. 마치며...
지금까지 AutoML에 대해 소개하고 실습까지 진행해봤습니다. 항상 컴피티션을 하면서 여러가지 전처리와 파라미터를 수정하며 최고의 성능을 뽑아내고자 시간을 썼는데 AutoML로 좋은 성능을 뽑아낼 수 있다는 것에 놀랐습니다. 앞으로 AutoML이 더 발전된다면 ML은 깊게 배우지 않아도 누구나 좋은 성능의 모델을 개발해낼 수 있을 것입니다.
'ML' 카테고리의 다른 글
| [ML] 머신러닝 기초 (4) Linear Regression 회귀 이론 (0) | 2024.02.15 |
|---|---|
| [ML] 머신러닝 기초 (3) 머신러닝 기본 수학 이론 (1) | 2024.02.14 |
| [ML] 머신러닝 기초 (2) 머신러닝 기본 용어 정리 (1) | 2024.01.31 |
| [ML] 머신러닝 기초 (1) 머신러닝 소개 (1) | 2024.01.29 |
| [ML]AutoML 소개 및 실습(feat.pycaret, H2O, TPOT, LightAUTOML)(1) (0) | 2022.12.30 |