1. INTRO
AutoML(Automated Machine Learning)은 자동화된 Machine Learning(자동화된 ML 또는 AutoML이라고도 함)은 시간 소모적이고 반복적인 기계 학습 모델 개발 작업을 자동화하는 프로세스입니다. 데이터 과학자, 분석가 및 개발자는 모델 품질을 유지하면서 확장성, 효율성 및 생산성이 높은 ML 모델을 빌드할 수 있습니다. AutoML은 머신러닝을 위한 고급 모델 구축을 자동화할 수 있기 때문에 데이터 과학 전문 지식과 프로그래밍 스킬이 필요한 공정을 기계가 알아서 처리해서 누구나 쉽게 머신러닝을 활용할 수 있도록 도와줍니다.
연구자들은 "AutoML과 같은 기술들이 결국 모델 최적화 과정을 훨씬 더 효율적으로 발전시킬 것" 라고 말했습니다.
요즘 Dacon이나 kaggle ML TASK 공모전 상위권 소스코드를 보면 AutoML을 활용해 몇줄 안되는 코드만으로도 좋은 성능을 보여주고 있습니다. 지금 이 순간에도 여러 AutoML library를 개발하고 업그레이드 하고 있으니 조금 더 시간이 지나면 머신러닝 연구자들을 대체할 수도 있다는 생각을 했습니다. 그렇기 때문에 트랜드를 쫓기 위해 여러 AutoML library에 대해 소개하고 제가 직접 구글링을 통해 정보를 찾아 봤을 때 많이 언급되고 사용하기 쉬운 4가지 pycaret, H20, TPOT, LightAutoML 실습까지 진행해보도록 하겠습니다.
실습 깃허브 코드
GitHub - moonjoo98/DACON: 2021~2022년에 참여한 DACON 공모전 정리입니다.
2021~2022년에 참여한 DACON 공모전 정리입니다. Contribute to moonjoo98/DACON development by creating an account on GitHub.
github.com
1. AutoML Library
1-1. LightAutoML
LightAutoML은 자동화된 기계 학습을 목표로 하는 오픈 소스 파이썬 라이브러리입니다. 그것은 텍스트 데이터로 다양한 작업에 대해 가볍고 효율적으로 설계. LightAutoML은 다음을 가능하게 하는 사용하기 쉬운 파이프라인 생성 기능을 제공합니다.
- Automatic hyperparameter tuning, data processing.
- Automatic typing, feature selection.
- Automatic time utilization.
- Automatic report creation.
- Graphical profiling system.
- Easy-to-use modular scheme to create your own pipelines.
1-2. H20 AutoML
H20 AutoML은 알고리즘 선택, Features 생성, 하이퍼파라미터 튜닝 및 반복 모델링을 자동화하는 기계 학습 프로젝트를 위한 최고의 AutoML 라이브러리 중 하나입니다. 기계 학습 프로젝트가 오류 없이 효율적으로 ML 모델을 훈련하고 평가하는 데 도움이 됩니다. 프로젝트 성능을 향상시키기 위해 기계 학습 전문 지식의 필요성을 줄입니다.
1-3. TPOT
TPOT는 예측 모델링 작업을 위한 고품질 기계 학습 모델을 자동으로 발견하기 위해 널리 사용되는 AutoML 라이브러리입니다. 그것은 Scikit-learn 데이터 preparation 및 기계 학습 모델이 있는 오픈 소스 라이브러리입니다. genetic programming으로 머신러닝 파이프라인을 최적화하는 파이썬 AutoML 툴입니다. 수천 개의 가능한 파이프라인 중에서 가장 적합한 것을 사용하여 규칙적이고 지루한 작업을 자동화하는 데 도움이 됩니다.
1-4. Pycaret
pycaret은 Machine Learning Workflow를 자동화하는 오픈소스 라이브러리입니다. Classification, Regression, Clustering등의 Task에서 사용하는 여러모델들을 동일한 환경에서 한번에 한줄의 코드로 실행할 수 있도록 자동화한 라이브러리입니디ㅏ. 여러모델을 비교할 수 있으며 각 모델 별로 튜닝을 진행할 수도 있습니다.
이 외에도 Auto-Sklearn, Auto-ViML, Auto-Keras, TransmogrifAi, MLBox, MLJAR : AutoML, FLAML, AutoGluon, Azure AutoML등 다양한 라이브러리가 있는데 너무 많아서 모든 AutoML 라이브러리를 사용해보지는 않았습니다. 각자의 장점이 있으므로 잘 살펴보고 라이브러리르 골라서 사용하는 것이 좋아 보입니다.
이 글에서는 위의 4가지를 실제 DACON Competition 데이터로 학습을 진행해보도록 하겠습니다.
2. 실습
2023-01-04 기준으로 진행중인 DACON 유전체 정보 품종 분류 AI 경진대회 데이터로 실습을 진행했습니다.
https://dacon.io/competitions/official/236035/overview/description
유전체 정보 품종 분류 AI 경진대회 - DACON
분석시각화 대회 코드 공유 게시물은 내용 확인 후 좋아요(투표) 가능합니다.
dacon.io
2-1. Pycaret

2-1-1. Setup() (data preprocessing)
pycaret setup함수를 사용한다면 복잡했던 데이터 전처리를 한줄의 코드로 간편하게 진행할 수 있습니다.
파라미터
● data : Input data를 입력해주시면 됩니다. Train, Test를 별도로 분리하지 않고 입력해주시면 뒤의 train_size에 입력한 비율대로 Train,Test를 split 합니다.
● target : 데이터셋에서 최종적으로 예측해야 하는 Column을 설정해주는 파라미터 입니다. data에서 지정해준 input data에 해당 column이 존재해야 가능합니다.
● session_id : Random seed를 설정해주는 부분입니다. 반복 실행을 진행 했을 때 동일한 결과를 나오도록 합니다.
● normalize : 데이터에 정규화를 할 것인지 True/False로 선택합니다.
● normalize_method : normalize를 True인 경우 어떤 방식으로 정규화를 진행할 것인지를 정합니다.
('minmax','maxabs','robust')
● transformation : Power Transformation을 통해서 데이터 샘플들의 분포가 가우시안 분포(정규 분포)에 더 가까워지도록 처리해주는 과정입니다.
● fold_strategy : Fold starategy전략을 선택해서 설정할 수 있는 하이퍼파라미터 입니다. pycaret은 기본적으로 10-fold Cross-Validation을 수행합니다.
이외에도 많은 파라미터가 존재하니 필요에 따라 찾아보고 지정해주면 될 것 같습니다.
지금까지 data split, normalize, transformation, fold setting 하나하나 힘들게 코드를 짜면서 진행해줬는데 정말 간편하게 한줄의 코드로 모든 전처리를 진행할 수 있습니다.
2-1-2. models() (check available models)
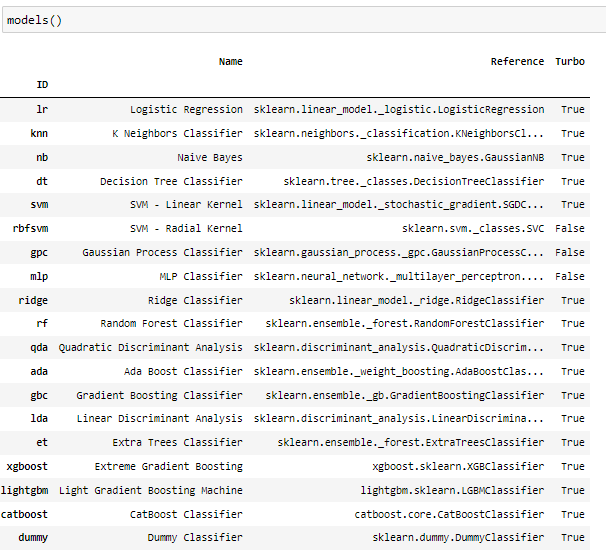
setup함수를 진행하고 models() 함수를 실행해보면 사용가능한 모델을 볼 수 있습니다. 여기서 원하는 모델을 불러와서 customizing을 할수도 있습니다.
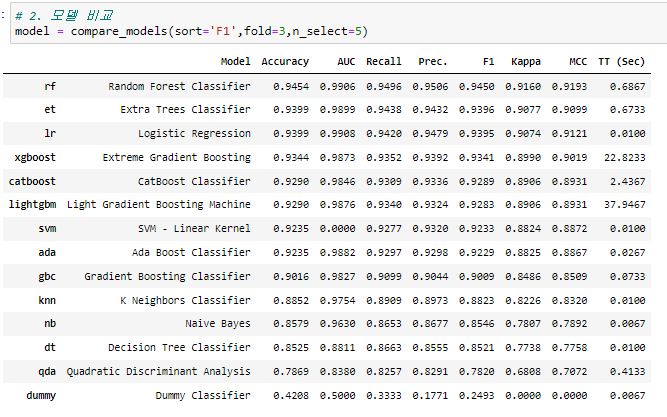
2-1-3. compare_models()
compare_models 함수를 사용하면 models()에서 사용가능한 모델의 성능을 비교해볼 수 있습니다. 여기서 성능 순으로 모델을 볼 수 있으니 task에서 성능이 좋게 나오는 모델을 쉽고 빠르게 찾아볼 수 있습니다.
파라미터
● n_select : 학습에 수행한 모델을 n_select에서 설정해준 수만큼 성능 순서대로 모델을 저장해줍니다.
● sort : Metric의 이름을 입력해주시면 됩니다. 어떤 metric의 기준으로 성능을 sort할지 지정해줍니다.
● include : 어떤 모델들을 비교할지 설정해주는 함수 입니다. 여기서 특정 모델을 포함할 수 있습니다.
● exclude : include와 반대로 특정 모델을 제거하고 비교할 수 있습니다.
● fold : fold를 지정해줄 수 있습니다.
컴피티션의 평가지표가 F1-SCORE이여서 sort를 f1으로 지정해줬고, train data가 256개로 매우 적은 수이기 때문에 fold를 최소한으로 했습니다.
성능 순으로 비교해봤는데 생각보다 성능이 좋다고 알려진 catboost, lgbm, xgboost가 오히려 randomforest보다 성능이 떨어진 것을 볼 수 있습니다. 이러한 경우 data set과 현재 model의 파라미터 세팅이 맞지않는 경우일 수 있습니다. 그러므로 파라미터 튜닝을 진행해줄 필요가 있습니다.
2-1-3. tune_model()
하이퍼 파라미터 튜닝도 간단하게 한줄의 코드로 진행할 수 있습니다.
앞서 저장된 best 5 model을 튜닝해보도록 하겠습니다.
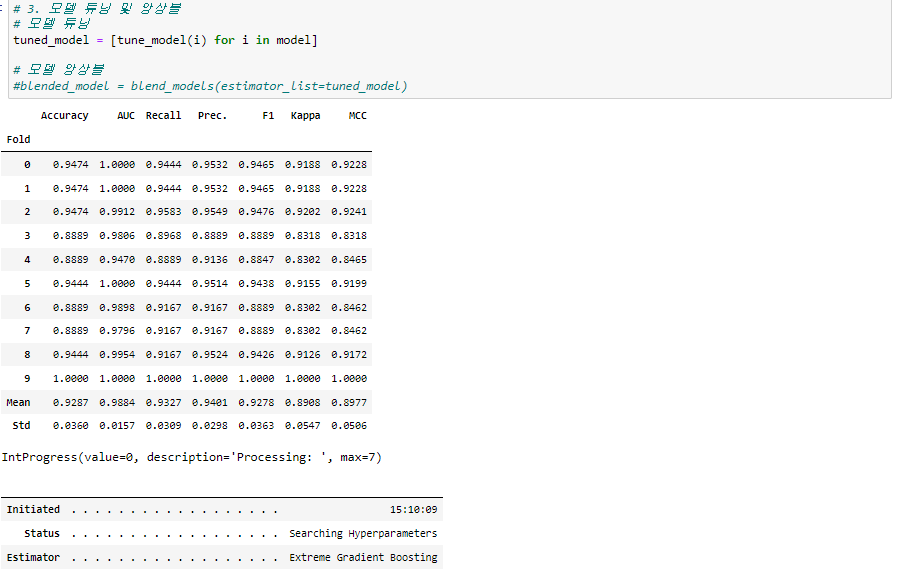
파라미터
● n_iter : 이 값을 크게 해줄수록 성능이 더 좋아질 가능성은 높지만 시간이 오래 걸려서 더 많은 시간이 걸리므로 사용하려는 task에 맞게 설정해주시면 됩니다.
● optimizer : 튜닝을 할 때 어떤 Metric을 기준으로 모델을 선별할 것인지 결정하는 하이퍼파라미터 입니다.
지금과 같은 컴피티션의 경우 n_iter의 값을 키워 성능 향상을 고려해볼 수 있습니다.
2-1-4. blend_models() (ensemble model)
상관관계가 낮은 여러 모델을 ensemble한다면 좀더 일반화된 모델을 만들고 overfitting을 줄일 수 있습니다.
pycaret에서는 blend_models()로 가볍게 ensemble을 할 수 있습니다.

파라미터
● estimatior_list : 사용하고자 하는 모델 리스트를 넣어줍니다. 저의 경우 앞서 하이퍼파라미터 튜닝을 진행한 5개의 모델을 넣어줬습니다.
● fold : fold를 설정해주시면 됩니다.
● method : soft와 hard가 있는데 soft가 성능이 좀 더 좋다고 합니다. task에 따라 다르니 둘다해보시면 좋을 것 같습니다.
● optimize : 평가하고자하는 metric을 지정해주시면 됩니다.
항상 복잡하게 진행한 ensemble을 하나의 코드로 간편하게 진행할 수 있습니다. 이렇게 ensemble 모델까지 만들었다면 마지막으로 infernce를 진행해보도록 하겠습니다.
2-1-5. finalize_model() (select final model)
최종적으로 사용할 모델을 finalize_model()안에 넣어주시면 됩니다
추가로 evaluate_model() 함수를 사용한다면 feature_importance등 다양한 기능을 확인하실 수 있습니다.
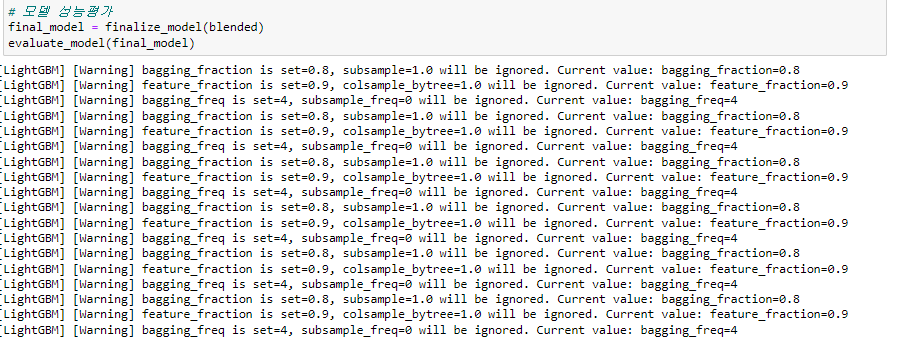
마지막으로 predict를 진행해보겠습니다.
2-1-6. predict_model()
간단하게 모델로 추론을 진행할 수 있습니다. 예측하고자 하는 test 데이터를 넣어주기만 하면 label과 score가 나옵니다.
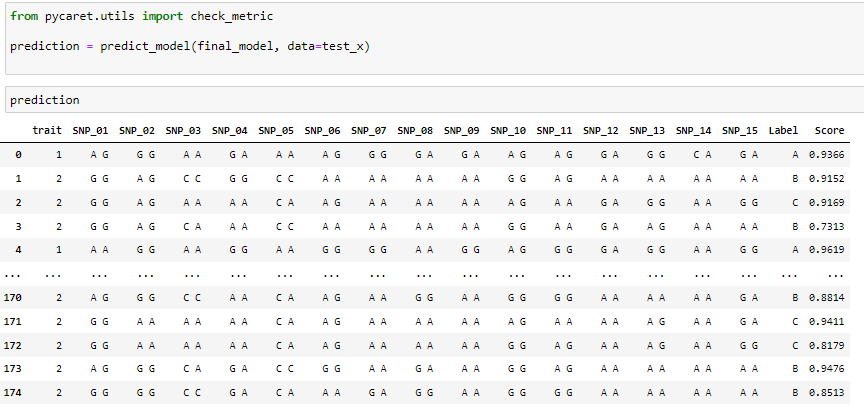
여기까지 pycaret으로 데이터 전처리부터 예측까지 진행해봤습니다.
leaderboard score는 0.96~7 사이를 왔다갔다 하는 것으로 확인했습니다. 지금까지 복잡하게 하나씩 진행하던 ML workflow를 단 몇줄의 코드로 끝내니 허무하기도 했지만 정말 편한것 같습니다. 이제 다음으로는 H20 AUTOML에 대해 실습을 진행해보도록 하겠습니다.
2-2. H20 AUTOML
H2O는 오픈소스 머신러닝 플랫폼으로 다양한 머신러닝 모형과 딥러닝 등을 구축하여 AutoML과 같은 최신 알고리즘을 제공합니다. 앞선 유전체 정보 품종 분류데이터를 그대로 활용해서 H20 AUTOML 실습을 진행해보도록 하겠습니다.
2-2-1 h2o.init()
h2o.init() 을 통해 h2o 인스턴스를 생성해야합니다. 성공적으로 h2o가 load되면 아래와 같이 출력이 되는 것을 확인할 수 있습니다. 메시지도 successful 기분좋은 메시지가 뜨게 될 것입니다.
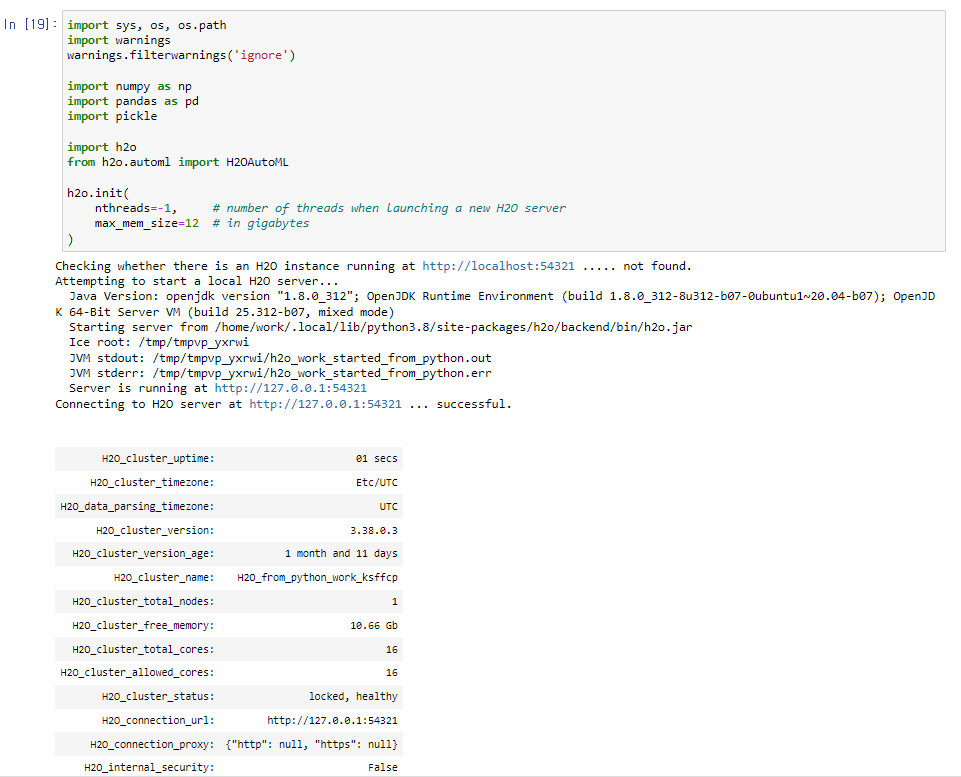
2-2-2. h2o.H20Frame (데이터 준비)
우선 h2o에는 H2OFrame이라는 자체 데이터프레임이 존재합니다. h2o.H2OFrame 함수를 이용하여 h2o에서 사용하기 위한 자체 데이터프레임을 구축합니다. 하지만 이 함수를 사용하지 않고 진행해도 무방합니다. 무슨 특별한 기능이 있는줄 알고 사용은 해봤지만 이 자체 데이터 프렝미에서 값을 추출하는게 어색하고 불편하기 때문입니다. 하지만 기본적을호 h2o에 대해 소개하는 글이기 때문에 H2OFrame을 사용해서 진행하도록 하겠습니다.
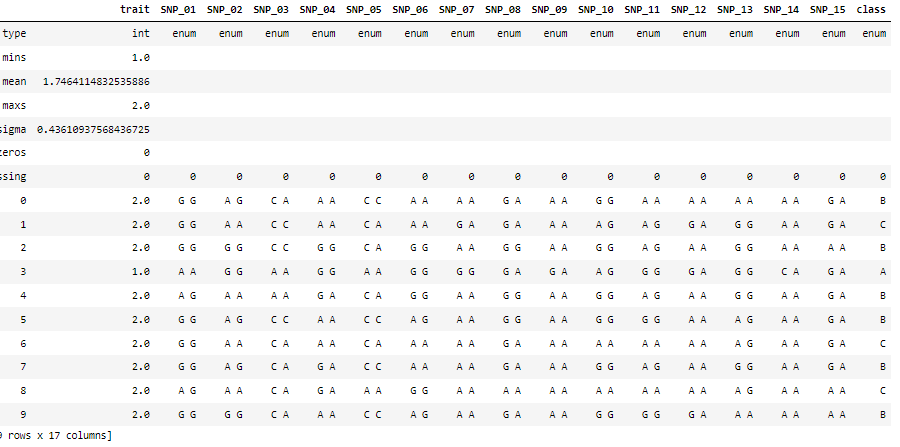
여기서 column명 trait을 보시면 category fearure이지만 type이 int로 들어가서 범주형 변수로 착각하게 된 것 같습니다. 직접 이부분을 수정해 새로 h2o데이터프레임을 구축했습니다.
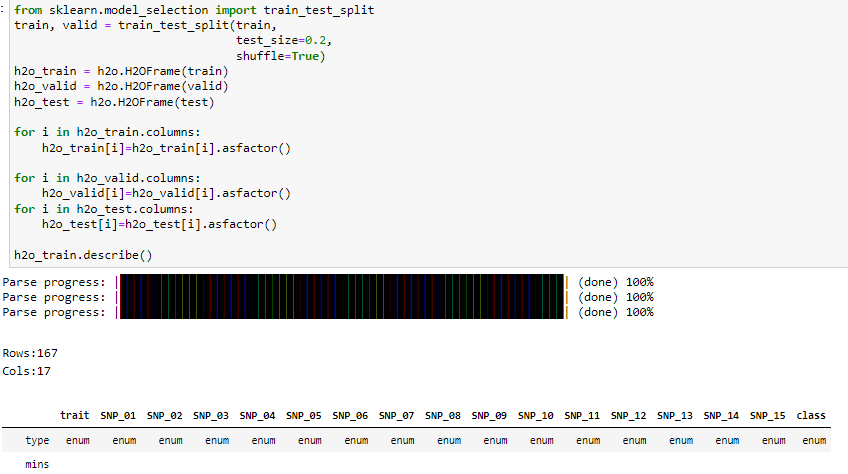
여기서 신기한것은 모두 동일한 값으로 되어있거나 의미가 없는 컬럼은 제거하고 데이터프레임을 구축한다는 점입니다. 위에서는 의미가 없는 컬럼은 이미 사전에 전처리를 진행했기 때문에 제거된 컬럼없이 모두 데이터프레임이 생성된 것을 보실 수 있습니다. 이러한 기능 때문에 H2OFrame을 사용하는 것이 좋을것 같기도 합니다.
이제 벌써 데이터 준비가 완료됐습니다. 다음으로 모델을 준비해보도록 하겠습니다.
2-2-3. H20AutoML (모델 준비)
모델 역시 간편하게 준비하고 학습을 시작할 수 있습니다.
파라미터
● max_runtime_secs : 최대 몇 초간 탐색을 할 것인지 정하는 파라미터 입니다. 지금과 같은 컴피티션의 경우 max_runtime_secs를 키워서 최대의 성능을 가지는 모델을 찾아내는 것이 좋을 수 있습니다.
● exclude_algos : 어떤 알고리즘은 제외할 것인지를 선언할 수 있습니다. 그리고 xgboost와 stackedEnsemble을 제외한 이유는 실습용이기 때문에 시간이 너무 오래걸리는 두 모델은 일부러 제외하고 진행했습니다. 컴피티션을 진행한다면 모든 모델을 넣고 돌리셔도 무방합니다.
학습 코드 (train)
x는 데이터의 colume의 feature 명, y는 label명을 넣어주시면 됩니다. training_frame은 학습 데이터를, validation_frame엔느 검증데이터를 넣어주시면 학습이 진행됩니다. max_runtime_secs를 6000으로 지정해줬기 때문에 6000초만 즉 1시간만기다려 보도록 하겠습니다.
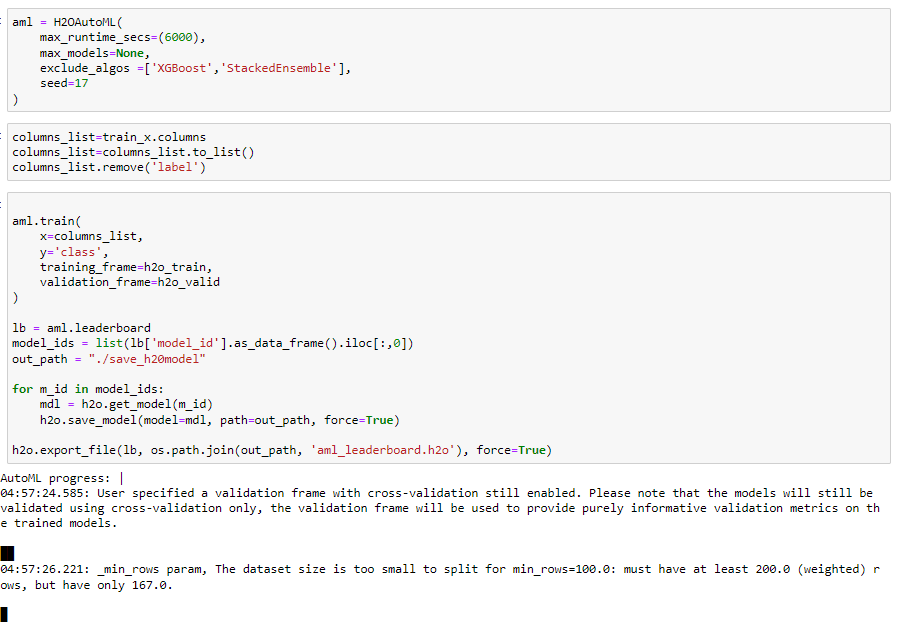
leaderboard
모델의 성능을 보기 위해 leaderboard함수로 리더보드를 볼 수 있습니다. 여기서 원하는 모델을 선택해서 사용하시면 됩니다. 그리고 모델을 save_model을 통해 원하는 경로에 저장하고 불러와 사용하실 수 있습니다.
export_file
leaderboard를 저장해 언제든 불러오실 수 있습니다.
2-2-4. model select
학습이 끝나고 import_file()을 통해 위에서 export한 leaderboard를 불러올 수 있습니다.
GBM이 가장 성능이 좋게 나온걸로 확인하실 수 있습니다.
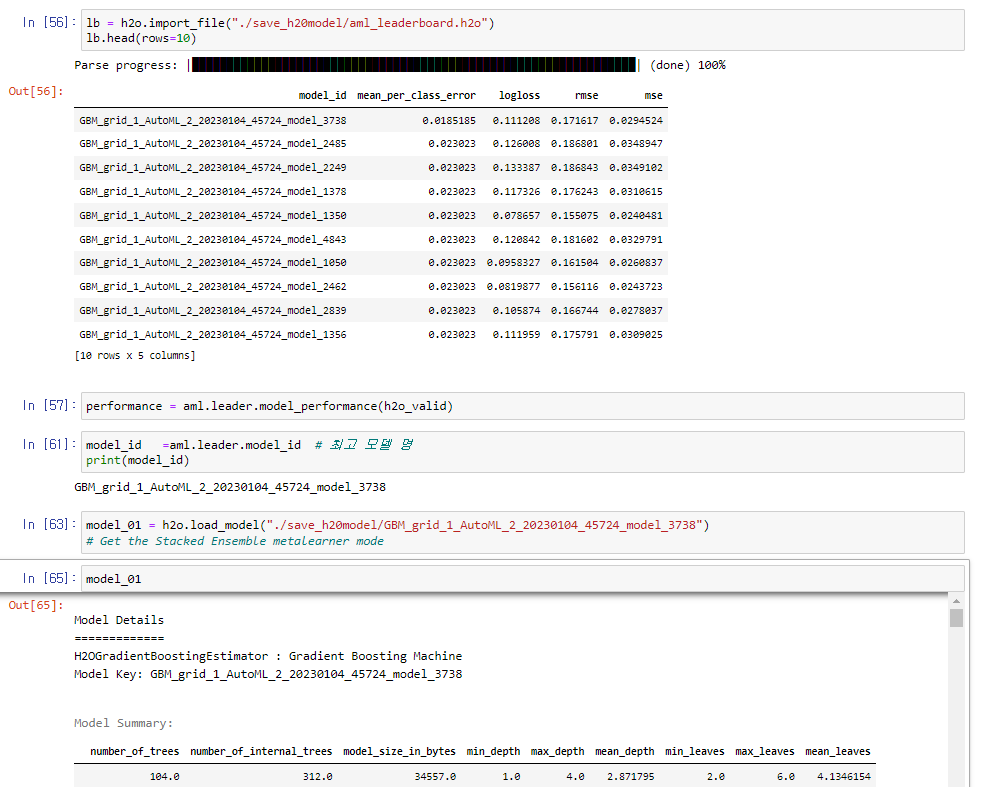
h2o.load_model()을 통해 저장해둔 경로의 best model을 load 하도록 합니다.
Feature imprtance
모델의 Feature importance도 쉽게 확인할 수 있습니다 trait가 생각보다 정말 중요한 변수였네요. 이걸로 파생변수를 만든다면 성능 향상이 기대가 됩니다.
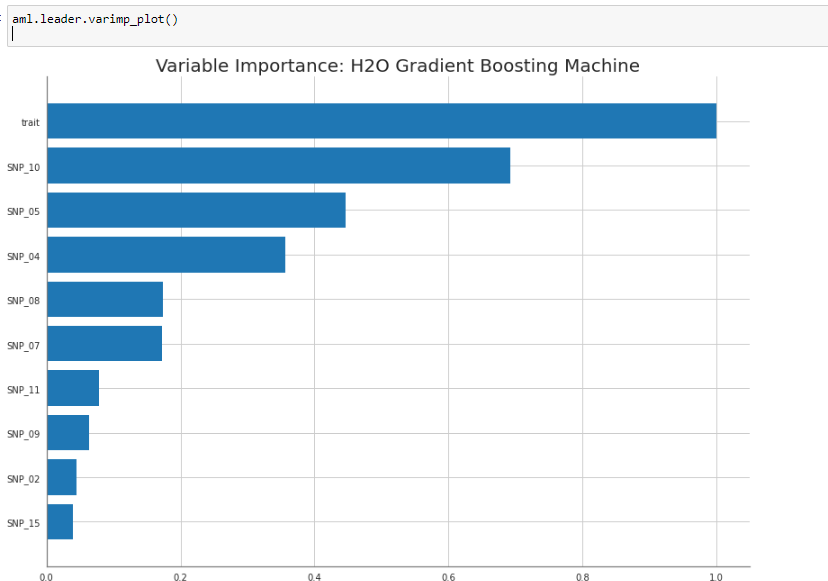
2-2-5. Predict (추론)
이제 best model도 찾았으니 test데이터 추론을 해보도록 하겠습니다.
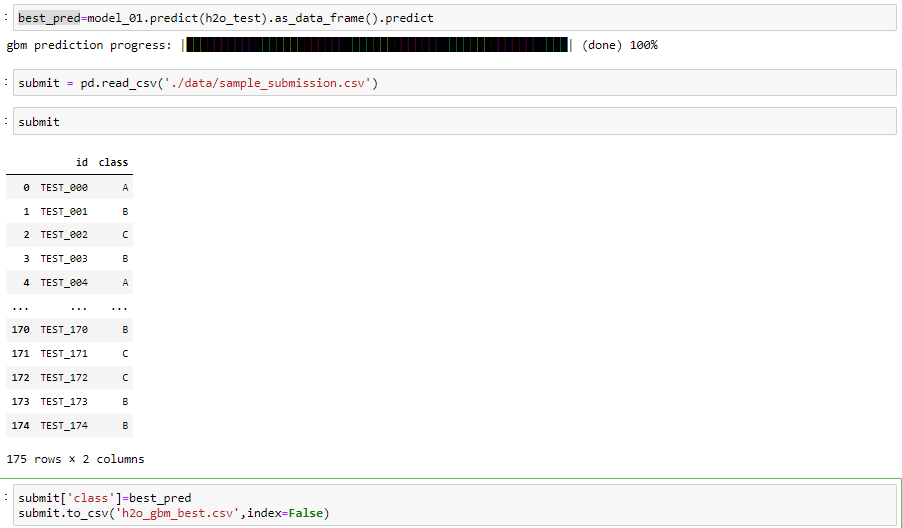
여기서 model.predict을 하게되면 h2o의 데이터프레임으로 값이 반환되므로 저희가 사용하기 편한 dataframe형식으로 변환해주기 위해 as_data_frame을 사용해 줬습니다. 이렇게 해서 결과값을 제출 해봤습니다.

피쳐엔지니어링 하나 없이 양호한 성능이 나오는 것으로 확인했습니다.
이상으로 h2o AUTOML은 끝내도록 하겠습니다.
글이 너무 길어지는 관계로 lightautoml과 TPOT은 다음 페이지에서 작성하도록 하겠습니다.
'ML' 카테고리의 다른 글
| [ML] 머신러닝 기초 (4) Linear Regression 회귀 이론 (0) | 2024.02.15 |
|---|---|
| [ML] 머신러닝 기초 (3) 머신러닝 기본 수학 이론 (1) | 2024.02.14 |
| [ML] 머신러닝 기초 (2) 머신러닝 기본 용어 정리 (1) | 2024.01.31 |
| [ML] 머신러닝 기초 (1) 머신러닝 소개 (1) | 2024.01.29 |
| [ML]AutoML 소개 및 실습(feat.pycaret, H2O, TPOT, LightAUTOML)(2) (0) | 2023.01.04 |