행렬(Matrix) vs 벡터(Vector) VS 스칼라(Scalar)

머신러닝에서 벡터와 행렬은 그리고 스칼라는 데이터를 표현하고 처리하는 데 사용되는 기본적인 수학적 구조입니다.
행렬(Matrix)
정의 : 행렬이란 숫자들을 행과 열로 구성된 직사각형 형태로 배열한 것입니다. 이는 여러 숫자들을 모아서 한번에 표현할 수 있다는 것인데, 다량의 데이터를 한번에 표현할 수 있는 좋은 수단이라는 것을 의미합니다. 이로 인해 머신러닝에서 행렬은 데이터 세트를 표현하거나 여러 데이터 포인트를 동시에 처리하는 데 자주 사용됩니다. 예를 들어, 여러 데이터 포인트가 각각의 행으로 구성되고, 각 행의 열이 다양한 특성을 나타내는 형식입니다.
표현 : 행렬은 행(row)과 열(column)로 구성됩니다. 예를 들어, MxN 크기의 행렬은 M개의 행과 N개의 열을 가집니다. 이를 통해 데이터를 2차원적으로 표현할 수 있습니다.
연산: 행렬 간에는 덧셈, 뺄셈, 곱셈 등의 연산이 가능합니다. 특히 행렬곱(matrix multiplication)은 머신러닝에서 중요한 역할을 합니다. 이를 통해 데이터의 변환, 특징 추출 등 복잡한 연산을 수행할 수 있습니다.
벡터(Vector)
정의 : 벡터는 숫자들의 순서화된 리스트입니다. 즉, N x 1차원의 행렬(Matrix) 입니다. 머신러닝에서 벡터는 주로 데이터 포인트를 나타냅니다. 예를 들어, 어떤 사람의 특징(키, 몸무게, 나이 등)을 나타내는 데 사용될 수 있습니다.
표현: 벡터는 일반적으로 열 벡터로 표현됩니다. 즉 하나의 열을 가지며 여러 개의 행만을 가지기 때문에 벡터 내부 데이터의 수가 곧 벡터의 차원(Dimension) 수가 됩니다.
연산: 벡터 간에는 덧셈, 뺄셈, 스칼라곱(벡터의 각 원소에 동일한 수를 곱하는 것) 등의 연산이 가능합니다. 또한, 벡터 간의 내적(dot product)을 통해 두 벡터 간의 유사성을 측정할 수 있습니다.
스칼라(Scalar)
스칼라(scalar)는 단일 숫자 값을 의미합니다. 머신러닝과 수학에서 스칼라는 벡터나 행렬과 달리 방향성이 없는 단순한 수량을 나타냅니다.
단일 값: 스칼라는 하나의 숫자로 표현되며, 이는 정수, 실수, 복소수 등이 될 수 있습니다. 예를 들어, 온도(30도), 거리(5킬로미터), 질량(2킬로그램) 등은 스칼라의 예입니다.
방향성 부재: 벡터가 방향과 크기를 가지는 것과 달리, 스칼라는 크기만을 가지고 방향성은 없습니다. 예를 들어, 스칼라는 5킬로미터, 벡터는 5킬로미터 북쪽입니다.
표현: 일반적으로 소문자로 표현되며, 보통 a, b, c 등의 알파벳으로 나타냅니다. 예를 들어, 스칼라 a는 숫자 5를 나타낼 수 있습니다.
머신러닝에서의 활용
행렬과 벡터
- 데이터 표현: 머신러닝 모델은 대부분 행렬과 벡터를 이용해 데이터를 표현합니다. 예를 들어, 이미지는 픽셀 값의 행렬로, 텍스트는 단어 빈도수의 벡터로 표현될 수 있습니다.
- 연산: 머신러닝 알고리즘은 벡터와 행렬 연산을 기반으로 데이터를 처리하고 학습합니다. 이는 컴퓨터가 빠르고 효율적으로 계산을 수행할 수 있게 해줍니다.
- 최적화: 많은 머신러닝 알고리즘에서는 비용 함수(cost function)나 목적 함수(objective function)를 최적화하는 과정에서 벡터와 행렬 연산이 사용됩니다.
스칼라
- 스칼라 연산: 머신러닝에서는 스칼라 값을 사용하여 벡터나 행렬의 각 요소에 곱하거나 더하는 등의 연산을 수행합니다. 이를 스칼라 곱셈(scalar multiplication)이라고 합니다. 벡터에 스칼라를 곱하면 벡터의 각 요소가 스칼라 값으로 곱해집니다.
- 파라미터와 하이퍼파라미터: 머신러닝 모델에서 많은 파라미터(parameter)와 하이퍼파라미터(hyperparameter)는 스칼라 값으로 표현됩니다. 예를 들어, 학습률(learning rate)이나 규제(regularization) 파라미터 같은 값들이 이에 해당합니다.
- 결과 값: 머신러닝 모델의 출력이나 성능 지표(performance metric)도 스칼라 값일 수 있습니다. 예를 들어, 분류 문제에서의 정확도(accuracy)나 회귀 문제에서의 평균 제곱 오차(mean squared error)는 스칼라 값으로 표현됩니다.
이처럼 벡터와 행렬 그리고 스칼라는 머신러닝의 기본적인 구성 요소로, 데이터의 표현부터 알고리즘의 구현까지 다양하게 활용됩니다.
사실 행렬과 벡터 그리고 스칼라에 대해 깊게 파고들면 책 한권 분량 (선형대수)처럼 양이 많기 때문에 이정도까지 정리하겠습니다.
Regression vs Classification
회귀 (Regression)
- 입력값 : 연속값(실수형), 이산값(범주형) 등 모두 가능.
- 출력값 : 연속값(실수형)
- 모델 형태 : 일반적인 함수 형태(eg. y = w1x + wo)
분류 (Classification)
- 입력값 : 연속값(실수형), 이산값(범주형) 등 모두 가능
- 출력값 : 이산값(범주형)
- 모델 형태 : 이진 분류라면 시그모이드 함수, 다중 분류라면 소프트맥스 함수를 포함한 형태
데이터의 구성
- 데이터는 피처와 라벨로 구성됨
- 이는 독립변수(피처)와 종속변수(라벨)로도 불림
- 라벨은 y로 표기하며, 라벨의 유무로 지도학습, 비지도학습을 구분
Feature (=attribute, 피처)
- 데이터 X의 특징, 혹은 항목을 의미
- N : 데이터 샘플 갯수, D : 피처의 갯수
- ex) 혈압, 몸무게, 나이
데이터는 X처럼 행렬로도 X1처럼 벡터로도 표현하기도 한다.
Parameter (=weight, 파라미터, 가중치)
- 주어진 데이터 말고, 모델이 가지고 있는 학습 가능한 파라미터 ex) w0, w1.... wD
Hyperparameter
- 모델 학습에 있어, 인간이 정해야하는 변수들
- 학습률, 배치 크기 등 존재
- AutoML라는 머신러닝이 스스로 학습할 수 있는 연구 분야가 등장.
Input (입력값) vs Output (출력값)
- Input : 모델(함수)에 입력되는 값으로 데이터의 피처 부분(x로 표기)
- Output : 모델로부터 출력되는 예측값 (y^로 표기)
학습 데이터
- 학습 데이터는 모델에게 패턴, 특징, 관계 등을 학습시키는 데 사용되며, 이를 통해 모델은 주어진 입력에 대해 예측이나 결정을 내릴 수 있게 됩니다.
- 학습 데이터의 구성은 피처에 해당하는 x와 라벨에 해당하는 y를 함께 세트로 제공해야 합니다.
평가 데이터
- 평가 데이터는 모델이 얼마나 잘 작동하는지 평가하는 데 사용됩니다.
- 학습 데이터와는 별도로 유지되며, 모델이 학습 과정에서 본 적이 없는 새로운 데이터여야 합니다.
- 평가 데이터를 사용하여 모델의 성능을 평가하고, 과적합(Overfitting)이나 일반화(Generalization) 문제를 확인할 수 있습니다.
머신러닝에서 모델을 학습할 때, 학습 데이터와 평가 데이터로 나눠 학습을 진행합니다.
- 이때, 평가 데이터를 모델 학습에 사용하면 안됩니다. 오직 모델의 성능 평가에만 사용되어야 합니다.
- 학습 데이터도 모델이 학습하는 과정에서 피처 부분만 가지고 정답을 예측합니다. 실제 정답인 y(라벨)값과 예측값을 비교하여 얼마나 틀렸는지 오차를 머신에 전달하면서 모델이 오차를 줄여가는 방향으로 업데이트되면서 학습이 진행됩니다.
저도 학부 시절에 헷갈렸던 개념이라 학습 데이터에 대해 다시 한번 짚고 넘어가겠습니다.
학습 데이터에서는 모델의 피처(x)와 라벨(y)을 함께 사용하여 학습을 진행한다고 알고계시는 분들이 많은데, 여기서 혼동이 생기실 수 있습니다. 헷갈리지 않도록 정확하게 표현하자면 학습 데이터는 y값을 직접적으로 사용하지 않고 간접적으로 사용합니다.
- y값(라벨)의 역할: 모델 학습에서 y값은 학습의 '지표'로 사용됩니다. 즉, 모델이 학습 데이터의 피처(X)를 기반으로 예측한 결과를 실제 y값과 비교함으로써 모델이 얼마나 잘 또는 못하고 있는지를 평가합니다.
- 학습 과정: 학습 과정은 모델이 피처(X)를 사용하여 예측을 수행하고, 이 예측 결과를 실제 y값과 비교하여 오차를 계 산하는 것을 포함합니다. 그런 다음, 이 오차를 최소화하는 방향으로 모델을 업데이트합니다.
- y값의 간접적 사용: 이렇게 볼 때, y값은 모델의 예측을 '가이드'하는 역할을 하며, 모델이 실제로 y값을 '학습하는' 것이 아니라, y값을 기준으로 예측 성능을 조정하고 개선하는 데 사용됩니다.
따라서, y값은 모델이 예측 결과의 정확성을 평가하고 모델을 적절하게 조정하는 데 필요한 중요한 정보를 제공하지만, 모델이 y값을 직접 '학습'한다기보다는 y값을 기반으로 자신의 예측을 조정하는 데 사용된다고 이해하는 것이 더 정확합니다.
선형 결합식(Linear Combination)
수학과 머신러닝에서 중요한 개념으로, 각각의 변수(또는 벡터)에 스칼라 가중치를 곱한 후 이들을 더해 하나의 새로운 값(또는 벡터)을 생성하는 방식을 말합니다. 기본적인 형태는 다음과 같습니다
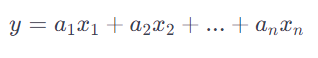
- 은 변수들(또는 벡터)입니다.
- 은 각 변수에 해당하는 스칼라 가중치입니다.
- 는 생성된 새로운 값(또는 벡터)입니다.
선형 결합식의 특징은 다음과 같습니다.
- 선형성: 각 변수는 선형적으로, 즉 곱하기와 더하기를 통해서만 조합됩니다. 복잡한 수학적 연산(예: 곱하기의 곱하기, 변수의 지수 등)은 포함되지 않습니다.
- 변수의 가중치: 각 변수는 특정한 가중치를 가지며, 이 가중치는 변수의 기여도나 중요도를 나타낼 수 있습니다.
- 범용성: 이 개념은 선형 대수학에서 널리 사용되며, 머신러닝에서도 선형 회귀, 선형 분류 등 다양한 알고리즘의 기초가 됩니다.
- 벡터 공간: 선형결합은 주어진 벡터들로부터 새로운 벡터를 생성합니다. 이렇게 생성된 모든 벡터들의 집합은 그 벡터들이 속한 벡터 공간을 형성합니다.
- 차원과 기저: 벡터 공간의 '차원'은 그 공간을 형성하는 데 필요한 최소한의 벡터 수, 즉 기저(basis) 벡터의 수로 정의됩니다. 선형독립인 최소한의 벡터들의 선형결합으로 벡터 공간의 모든 벡터를 표현할 수 있습니다.
기저 벡터 - 특정한 Vector Space를 Span(구성)해주는 선형 결합 벡터들의 최소 개수
머신러닝에서는 데이터와 파라미터 사이의 관계가 1차식 (x의 차수가 1)으로 결합된 형태를 갖고 있을 때 선형회귀라 하며데이터 포인트를 벡터로 간주하고, 이들의 선형결합을 사용하여 다양한 작업을 수행합니다. 예를 들어, 선형 회귀 모델은 독립 변수들의 선형결합을 사용하여 종속 변수를 예측합니다.
선형 모델 vs 비선형 모델
선형 모델과 비선형 모델은 머신러닝에서 데이터의 관계를 모델링하는 방식에 따라 분류되는 두 가지 모델 유형입니다. 이는 선형 결합식으로 표현이 가능한 모델인지 아닌지로 구분할 수 있습니다. 즉, Y= ax+b 일차함수 식에서 a라는 파라미터 계수가 1차식으로 x라는 피처와 선형결합이 되어있는지 확인하시면 됩니다.
선형 모델 (Linear Models)
- 선형 모델은 데이터의 특성이 종속 변수와 선형 관계를 가진다고 가정합니다. 즉, 각 입력 특성의 가중 합으로 출력을 예측합니다.
- 기본적인 형태는 y = w1*x1 + w2*x2 + ... + wn*xn + b와 같습니다. 여기서 x1, x2, ..., xn은 특성, w1, w2, ..., wn은 가중치, b는 편향(절편)입니다.
- 선형 모델은 해석하기 쉽고 계산이 간단하지만, 복잡한 패턴이나 비선형 관계를 모델링하는 데는 한계가 있습니다.
비선형 모델(Non-linear Models)
- 비선형 모델은 데이터의 특성과 종속 변수 사이에 비선형 관계가 있다고 가정합니다. 이러한 모델은 복잡한 패턴이나 관계를 포착할 수 있습니다.
- 비선형 모델은 단순한 선형 결합을 넘어서는 방식으로 데이터를 처리합니다. 예를 들어, 다항식, 지수, 로그, 시그모이드 함수 등을 사용할 수 있습니다.
- 비선형 모델은 복잡한 데이터 구조를 더 잘 포착할 수 있지만, 선형 모델보다 해석하기 어렵고 계산 비용이 더 높을 수 있습니다.
이 두 모델 유형은 데이터의 복잡성, 문제의 특성, 모델의 해석 가능성 등 다양한 요인을 고려하여 선택됩니다. 일반적으로, 데이터가 복잡하거나 비선형 패턴을 가질 때는 비선형 모델이 더 적합할 수 있으나, 모델의 해석성이 중요한 경우에는 선형 모델이 유리할 수 있습니다.
아래 메타코드의 머신러닝 기본 이론(1) 강의를 들으면서 진행하시는 목차에 맞게 이번 글에서는 기본 용어에 대해 정리해봤습니다. 그 과정에서 학부 시절에 배웠던 내용을 복기하여 직접 용어의 설명을 추가하고, 헷갈렸던 부분에 대해서는 좀 더 자세하게 적어봤습니다. 다음 글에서는 이제 머신러닝의 기본 수학 이론에 대해 작성하겠습니다.
https://mcode.co.kr/video/list2?viewMode=view&idx=21
메타코드M
빅데이터 , AI 강의 플랫폼 & IT 현직자 모임 플랫폼ㅣ메타코드 커뮤니티 일원이 되시기 바랍니다.
mcode.co.kr
'ML' 카테고리의 다른 글
| [ML] 머신러닝 기초 (4) Linear Regression 회귀 이론 (0) | 2024.02.15 |
|---|---|
| [ML] 머신러닝 기초 (3) 머신러닝 기본 수학 이론 (1) | 2024.02.14 |
| [ML] 머신러닝 기초 (1) 머신러닝 소개 (1) | 2024.01.29 |
| [ML]AutoML 소개 및 실습(feat.pycaret, H2O, TPOT, LightAUTOML)(2) (0) | 2023.01.04 |
| [ML]AutoML 소개 및 실습(feat.pycaret, H2O, TPOT, LightAUTOML)(1) (0) | 2022.12.30 |