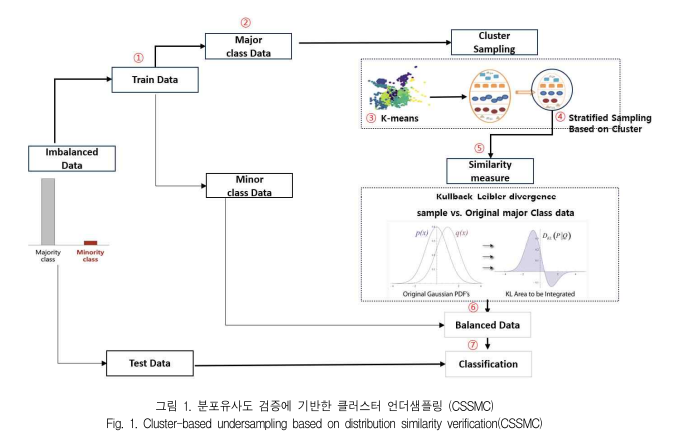
1. 서론http://ki-it.com/xml/40725/40725.pdf 클래스 불균형 데이터 분류 예측을 위한 클러스터 기반 언더샘플링 기법 (2024) 신용카드 사기 탐지나 장애 탐지 등 이상 탐지 분야에서는 다수클래스와 소수클래스가 불균형하게 분포하며 분류예측 성능에 많은 오류를 야기합니다. 해당 논문에서는 Kullback-Leibler Divergence을 활용하여 다수클래스의 모집단 분포를 반영하는 Cluster 기반 언더샘플링 방법을 제안했습니다. 이 방법은 다수클래스 데이터와 확률분포가 가장 유사한 샘플을 추출함으로써 언더샘플링의 주요 단점인 정보손실을 최소화합니다. 2. 본문기존의 언더샘플링 기법은 다수클래스와 소수클래스 분포에 따라 데이터 축약의 효과가 미미하거나, 대표성이 떨어져 오히..